Path not correctly configured for failover
Il y a quelque temps, nous avons du décommissionner une vieille baie HP EVA (qui nous coutait plus cher en maintenance que d’acquérir une baie neuve) et migrer les LUNs vers une baie EMC VNX, elle encore sous maintenance. Cependant, lorsque la migration a été faite, le consultant qui s’est chargé de reconfigurer multipath pour migrer d’une baie à l’autre l’a un peu fait « rapidement ».
Quelques mois plus tard, lors d’une maintenance classique sur une des baies EMC, de grosses anomalies ont été détectés. Lors de la coupure d’un contrôleur pour mise à jour, certains serveurs hébergeant une partie de nos progiciels, encore sous Redhat 4, se bloquaient au niveau I/O au lieu de basculer sur les chemins encore disponibles. L’occasion rêvée pour refaire un peu de multipath !
Dans cet article, je vais donc passer en revue quelques unes des erreurs que j’ai pu rencontrer, et comment les corriger.
Liloo Dallas Multipath ?

D’abord un bref rappel.
Pour ceux qui ne connaissent pas multipath, il s’agit d’un module de Linux qui permet de gérer les chemins multiples vers une même disque. On l’utilise sur des réseaux de stockage d’entreprises qui disposent de plusieurs niveaux de tolérance aux pannes.
Chacun des chemins SAN menant à un même disque (LUN A sur le schéma ci dessus) sont indexés côté OS par leur propre special device du type /dev/sd[n] (4 chemins : sde, sdf, sdg et sdh dans l’exemple).
On ne peut pas directement les utiliser puisqu’on utiliserait dans ce cas là qu’un seul des chemins disponibles. Et écrire en direct sur 2 chemins menant vers un même disque en même temps serait catastrophique.
Heureusement, Multipath détecte de lui même (via l’UUID du disque) que les chemins sont en fait un même périphérique et créé pour nous un fichier spécial /dev/dm-[n] qui permet de pointer vers le disque via l’ensemble de ses chemins.
Vérifier le plus évident
Initialement, l’anomalie n’était pas visible car les vérifications de l’état de multipath n’avaient été faites qu’avec le niveau de détail standard : les chemins sont bien déclarés, visibles et fonctionnels… RAS de ce côté.
# multipath -l
mpath9 (36006016067302f00e4588d06345ee111)
[size=100 GB][features="1 queue_if_no_path"][hwhandler="1 emc"]
\_ round-robin 0 [active]
\_ 0:0:5:3 sdd 8:48 [active]
\_ 1:0:5:3 sdh 8:112 [active]
\_ round-robin 0 [enabled]
\_ 0:0:4:3 sdc 8:32 [active]
\_ 1:0:4:3 sdg 8:96 [active]
[…]
De même les modules multipath étaient bien chargés dans le kernel :
# lsmod |grep dm
dm_mirror 32585 0
dm_round_robin 5185 1
dm_emc 7745 1
dm_multipath 22865 3 dm_round_robin,dm_emc
dm_mod 76585 7 dm_mirror,dm_multipath
Cependant, le démon multipathd qui permet de gérer les bascules de chemins est lui hors service…
# service multipathd status
multipathd est arrêté
ATTENTION : Le démarrage du démon multipath peut éventuellement provoquer une coupure des chemins, ce qui va planter le serveur et les traitements en cours. Il faut donc bien prendre garde que le serveur ne soit pas utilisé lors de son activation.
chkconfig multipathd on
chkconfig --add multipathd
Doublons dans les user-friendly device names
Une fois les problèmes basiques réglés, nous avons remarqué que le consultant en question ne s’était pas trop embêté avec les user-friendly names. Voici ce que la commande suivante renvoyait :
# multipath -v2
remove: mpath9 (dup of mpath2)
mpath9: map in use
remove: mpath23 (dup of mpath2)
mpath23: map in use
Bien que non bloquant, ceci est clairement peu élégant ;-).
Comme je l’explique plus haut, multipath agrège les /dev/sd[n] en un seul et unique /dev/dm-[n]. Cependant, il est déconseillé d’utiliser directement le fichier /dev/dm-[n]. En effet, tout comme les /dev/sd[n] (que ce soit dans le cadre de multipath ou pas d’ailleurs), les fichiers /dev/dm-[n] sont susceptibles de changer au cours de la vie du serveur ! De quoi avoir une mauvaise surprise après maintenance…
Pour résoudre ce problème, plusieurs solutions sont conseillées. Soit on utilise le WWID du disque qui est garanti unique, soit on utilise le device mapper qui transpose ce dm-[n] un user-friendly name du type /dev/mpath[n].
Dans le cas présent, au gré de la migration, les WWID avaient générés plusieurs mpath pour un même disque et il n’y avait plus de cohérence !
Pour régler le problème, le plus simple est de couper toutes les applications, puis d’effacer la configuration (pas les données, hein, juste les chemins et la table de correspondance) pour repartir de zéro. On récupère les WWID de chaque disques, puis on supprime tous les chemins courants avec les commandes suivantes :
multipath -ll #affiche les chemins et leurs informations
multipath -F #flush de tous les chemins enregistrés
Une fois les chemins supprimés, il faut modifier le fichier de configuration /etc/multipath.conf pour y ajouter en fin de fichier la déclaration des WWID à associer à des friendly_names fixés manuellement :
[...]
multipaths {
multipath {
wwid "360060160da302f009cd38abe2f5ee111"
alias mpath0
}
multipath {
wwid "36006016067302f00e458ad06345ee111"
alias mpath2
}
}
En enfin, on peut les réenregistrer à l’aide de la commande :
multipath -v2
Mode ALUA 4/PNR 1 pour les LUNs
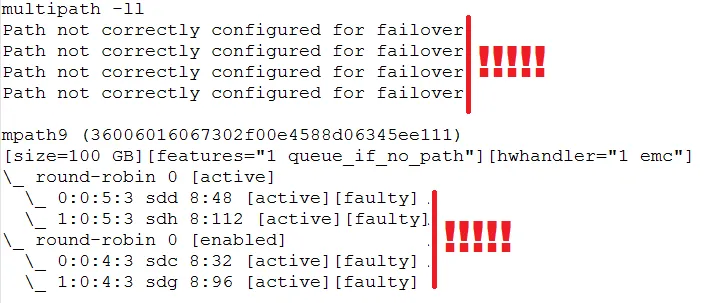
Pour autant, la vraie cause de l’anomalie n’a pu être détectée que lorsque le mode de détails supérieur a été utilisé pour afficher les chemins (option -ll). Plusieurs messages d’erreurs relativement explicites se sont affichés, et notamment :
- la mention Path not correctly configured for failover
- les chemins en « [active][faulty] »
multipath -ll
Path not correctly configured for failover
Path not correctly configured for failover
Path not correctly configured for failover
Path not correctly configured for failover
mpath9 (36006016067302f00e4588d06345ee111)
[size=100 GB][features="1 queue_if_no_path"][hwhandler="1 emc"]
\_ round-robin 0 [active]
\_ 0:0:5:3 sdd 8:48 [active][faulty]
\_ 1:0:5:3 sdh 8:112 [active][faulty]
\_ round-robin 0 [enabled]
\_ 0:0:4:3 sdc 8:32 [active][faulty]
\_ 1:0:4:3 sdg 8:96 [active][faulty]
Après consultation de ressources en lignes et du « [Host Connectivity Guide for Linux][3] », il apparait que le mode « ALUA 4 actif actif» n’est pas supporté sur les serveurs Redhat Entreprise Linux 4. Il faut utiliser le mode « PNR 1 actif passif» qui lui est bien certifié.
Dans notre cas, c’est pourtant bien ce mode « ALUA 4 » qui avait été déclaré côté baie EMC pour les chemins vers l’hôte. A l’inverse, la configuration qui avait été appliquée côté serveur était bien en mode « PNR 1 ». Il y avait donc une incohérence de ce côté-là.
Changer le mode des LUNs sur une baie VNX
La modification du type de Failover pour un LUN donné peut se faire depuis la console Unisphere mais ce n’est pas évident à trouver !
Une fois connecté, il faut choisir une des baies, ouvrir le menu « Hosts » puis « Host List ». Sélectionner le serveur concerné dans la liste, puis ouvrir l’onglet « Initiators » en bas de page.
Sélectionner un port, puis cliquer sur « Edit », et reconfigurer les 4 chemins.
Valider, et recommencer l’opération autant de fois que nécessaire.
Le mot de la fin
Dans notre cas, beaucoup d’erreurs avaient été faites lors de la configuration des LUNs, de la baie de disques et de multipath. Ça donne donc un bon tour d’horizon des premières choses à vérifier si jamais votre multipath sous Linux fonctionne mal.
Lorsque vous avez comme nous des baies EMC, j’aimerais insister sur le fait que le Host Connectivity Guide for Linux (lien mort, j’utilise Internet Archive) est vraiment un document très important, qui vous aidera à correctement tout configurer. N’hésitez pas à le lire en détail !