Proxmox et Prometheus sont dans un bateau…
Si vous avez suivi le précédent article sur Prometheus et Grafana, vous m’avez peut être vu teaser cet article.
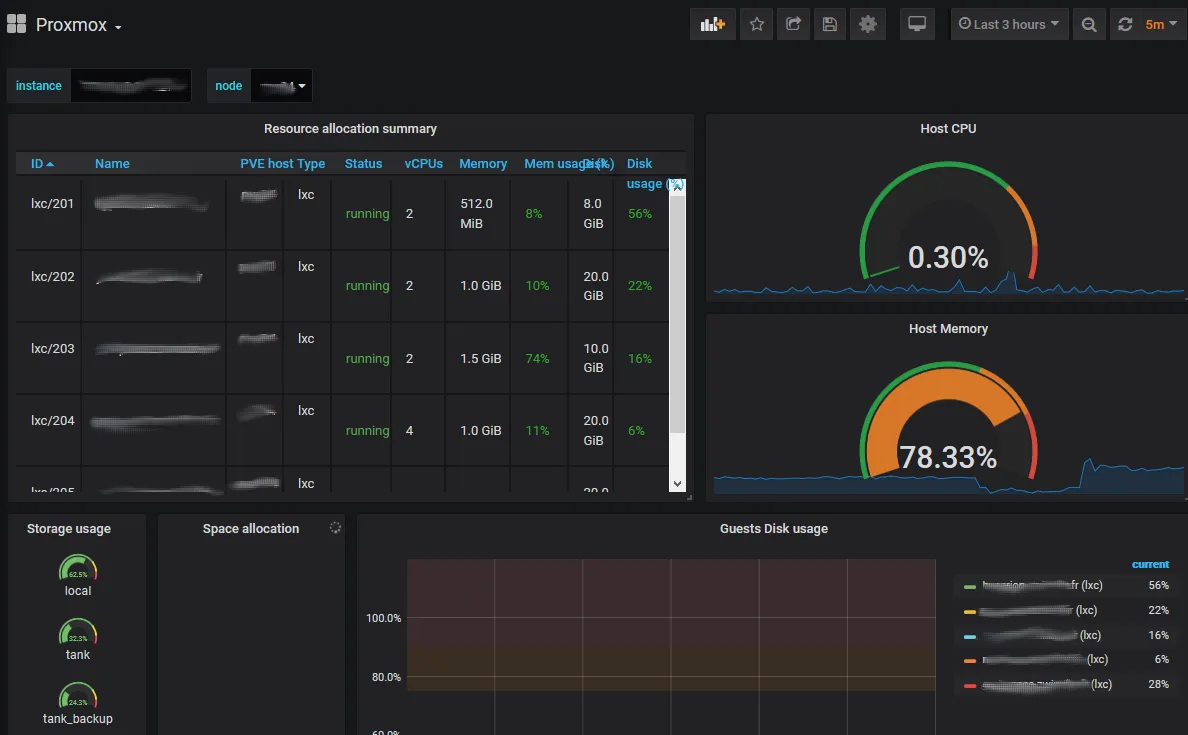
En effet, j’avais mis une capture d’écran d’un dashboard Grafana avec des métriques provenant de mon cluster Proxmox VE :
On fait du LXC à fond ici !caption>
Petit récap’
Pour rappel, dans le tuto précédent, on avait installé le couple Grafana + Prometheus sur une machine virtuelle (ou physique peu importe), et pas dans un container (comme le préconise la plupart des billets de blogs que j’ai pu lire). Maintenant vous comprenez surement mieux pourquoi ;-).
Pour alimenter notre Prometheus, on va donc vouloir le donner à manger. Et quoi de mieux dans une infrastructure non containerisée que les métriques de l’hyperviseur ?
prometheus-pve-exporter
On est plutôt gâté avec Proxmox VE, car les métriques pertinentes sont assez nombreuses et surtout exposées par API.
S’il n’existe pas d’exporter officiel, il existe néanmoins des implémentations Open Source réalisées par de gentils contributeurs.
La plus utilisée semble être celle de znerol, qui a en plus l’avantage d’être la base utilisée dans un dashboard sur le site de Grafana (on y reviendra). Dans la mesure du possible, j’essaye de rester sur les implémentations les plus couramment utilisées. Sauf exception, ça permet d’éviter d’être le seul à avoir un bug. Je vous ai mis une autre implémentation dans les sources en bas d’article, que je n’ai pas testée.
Les sources et la documentation sont disponibles sur Github à l’adresse suivante : github.com/znerol/prometheus-pve-exporter
Prérequis
Dans tous les cas, on va devoir créer un utilisateur dans Proxmox VE, a qui on va autoriser l’accès aux métriques depuis l’API. C’est cet utilisateur qu’utilisera notre exporter pour se connecter à PVE, récupérer les métriques et enfin les exposer au format OpenMetrics.
Sur un des serveurs PVE du cluster :
- créer un groupe
- ajouter le rôle PVEAuditor au groupe
- créer un utilisateur
- lui ajouter le groupe, puis un mot de passe
pveum groupadd monitoring -comment 'Monitoring group'
pveum aclmod / -group monitoring -role PVEAuditor
pveum useradd pve_exporter@pve
pveum usermod pve_exporter@pve -group monitoring
pveum passwd pve_exporter@pve
Installation de l’exporter
A partir de là, on peut installer l’exporter sur nos serveurs PVE. L’avantage du cet exporter c’est qu’il sait gérer le cluster. Je veux dire par là qu’avec un seul exporter vous allez pouvoir collecter l’ensemble des métriques de l’ensemble de vos machines du cluster (containers, VMs, stockage, hyperviseurs, …).
En théorie, il n’est donc nécessaire de l’installer que sur une machine. Pour autant, je vous conseille quand même d’installer un exporter par serveur. Dans les faits, cela vous évitera de perdre toute collecte de données de supervision en cas de panne du seul serveur portant l’exporter.
Sur vos serveurs PVE, lancer les commandes suivantes :
apt-get install python-pip
pip install prometheus-pve-exporter
Cette implémentation utilise le gestionnaire de paquet de Python, pip.
On va ensuite créer un fichier de configuration qui va contenir les informations de connexion à notre PVE :
mkdir -p /usr/share/pve_exporter/
cat > /usr/share/pve_exporter/pve_exporter.yml << EOF
default:
user: pve_exporter@pve
password: myawesomepassword
verify_ssl: false
EOF
Note : remplacer myawesomepassword par un mot de passe vraiment cool.
Temporairement, vous pouvez lancer le binaire manuellement pour voir si ça fonctionne correctement :
/usr/local/bin/pve_exporter /usr/share/pve_exporter/pve_exporter.yml
Si tout s’est bien passé, on va maintenant créer un script de démarrage systemd pour que notre exporter se démarre tout seul avec l’hyperviseur :
cat > /etc/systemd/system/pve_exporter.service << EOF
[Unit]
Description=Proxmox VE Prometheus Exporter
After=network.target
Wants=network.target
[Service]
Restart=on-failure
WorkingDirectory=/usr/share/pve_exporter
ExecStart=/usr/local/bin/pve_exporter /usr/share/pve_exporter/pve_exporter.yml 9221 192.168.1.1
[Install]
WantedBy=multi-user.target
EOF
Note : remplacer 192.168.1.1 par l’adresse IP de votre serveur Proxmox VE (aussi accessible par votre serveur Prometheus)
systemctl daemon-reload
systemctl enable pve_exporter
systemctl start pve_exporter
La collecte
On a maintenant un endpoint au format OpenMetrics qui peut être collecté par Prometheus. Cool !!
Le but du jeu va être maintenant d’informer Prometheus qu’il doit scrapper notre exporter. On va faire ça en ajoutant la configuration suivante à notre serveur Prometheus (puis le redémarrer) :
vi /usr/share/prometheus/prometheus.yml
[...]
scrape_configs:
[...]
- job_name: 'pve'
static_configs:
- targets:
- 192.168.1.1:9221 # Proxmox VE node with PVE exporter.
- 192.168.1.2:9221 # Proxmox VE node with PVE exporter.
metrics_path: /pve
params:
module: [default]
systemctl restart prometheus.service
Note : remplacer les IPs par les adresses IP de vos exporters sur vos serveurs PVE.
Visualiser tout ça
Dernière étape avant d’aller prendre un café, afficher tout ça dans un dashboard. Là ça aurait pu être trivial mais j’ai du bidouiller (un tout petit peu).
Je l’ai dis au début de l’article, un des avantages de cet exporter, c’est que quelqu’un a pris la peine de faire un dashboard dans Grafana qui affiche déjà tout sans qu’on ait besoin de faire quoique ce soit.
On peut donc l’installer juste en copiant l’URL ou l’ID dans notre Grafana 10347
Trivial !
La seule petite difficulté, c’est que ce Dashboard gère mal le clustering. Plus particulièrement, il n’aime pas qu’un meme exporter remonte les données de plusieurs nodes, ce qui est dommage pour un cluster.

J’ai donc tweaké le Dashboard en y ajoutant une variable “node”, permettant de sélectionner les métriques du node qu’on veut (uniquement).
Enfin, j’ai modifié les graphiques concernés en ajoutant un filtre de type id="node/$node" utilisant cette variable dans la requête PromQL.

Vous avez maintenant un Dashboard qui remonte les métriques de vos serveurs, stockages, vms et containers dans Proxmox VE ! A vous l’observabilité !
Sources
Une autre implémentation : wakeful/pve_exporter