DRBD
En 2015, j’avais voulu essayer la solution de stockage distribué DRBD. Et oui, 2015. C’est mon plus vieux brouillon sur le blog que je sors enfin. Vous vous en doutez, j’ai du repasser dessus pour ne pas vous donner de versions antédiluvienne ;-)
DRBD (pour Distributed Replicated Block Device) est donc un logiciel disponible sous Linux et Windows qui permet de gérer des périphériques de stockages virtuels utilisables dans des infrastructures.
Ces périphériques ont la particularité de pouvoir être « distribués » sur plusieurs serveurs sur un réseau de façon synchrone ou asynchrone et disposant de plusieurs méthodes de resynchronisation en cas de perte de lien ou d’incohérences.
L’avantage de cette solution est qu’elle est robuste (fiabilité éprouvée) et qu’elle permet de répondre à des problématiques de haute disponibilité et de performance que n’offrent pas forcément toutes les solutions de stockage.
Si cette solution peut paraître de prime abord un peu datée à l’époque des containers et de Kubernetes, sachez que Linbit a fait un effort assez conséquent justement sur cette partie, en essayant de se positionner comme un des acteurs du stockage distribué pour les architectures containerisées et/ou “cloud native” (surtout trusté par Ceph/CephFS, voire Gluster).

Prérequis
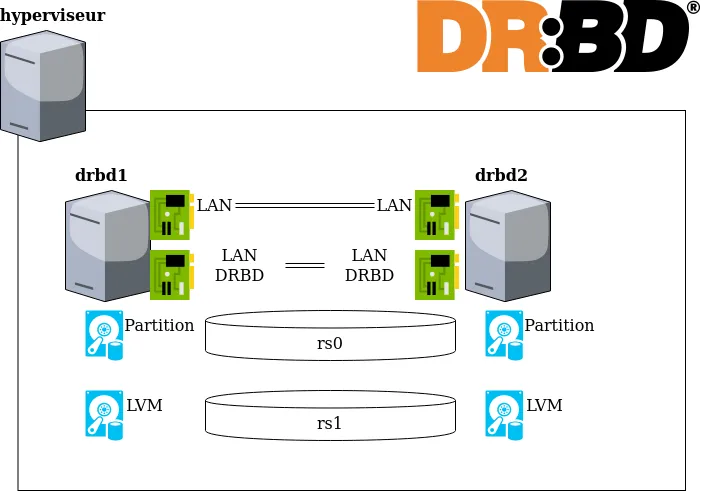
Pour tester DRBD, vous l’aurez compris, il va nous falloir au minimum deux serveurs. Pour faire simple, je vais utiliser des machines virtuelles (mais évidemment ça fonctionnera mieux sur un serveur physique) sur lesquelles j’ai installé une image Ubuntu 18.04.
Dans mon cas, j’ai rajouté des disques virtuels de 16Go, pour simuler des disques physiques à synchroniser. De même, j’ai également rajouté des interfaces réseaux supplémentaires pour simuler un réseau dédié « stockage ».
Installation du logiciel
La société LINBIT qui distribue le logiciel DRBD propose des packages précompilés pour la plupart des distributions Linux classiques. L’ensemble des packages des différentes versions de DRBD sont disponibles sur le site de Linbit. Cependant, ces packages « officiels » précompilés nécessitent d’avoir payé le support.
Note : Si les packages officiels sont réservés aux personnes qui payent le support, les sources, elles, sont bien entendu disponibles sur le site.
Heureusement, il est possible d’utiliser tout simplement les packages précompilés de votre distribution.
A la base, quand j’avais écrit le tutoriel en 2015, j’avais des soucis de compatibilité entre la version du kernel et drbd de ma distribution CentOS (6.3 à l’époque…). Ma version, 2.6.32-279 alors que les versions 8.3 et 8.4 de DRBD nécessitent le kernel 2.6.32-431. Mais rien ne vous empêche d’installer le kernel demandé pour résoudre ce problème.
Pour ce tuto, voici les commandes que j’ai dû utiliser pour installer DRBD 9 (la dernière stable même si la 10 arrive bientôt) sur mes Ubuntu 18.04.
sudo apt update
sudo apt upgrade
sudo apt install software-properties-common
sudo add-apt-repository ppa:linbit/linbit-drbd9-stack
sudo apt-get update
sudo apt install drbd-utils python-drbdmanage drbd-dkms
Une fois que c’est installé, testez que tout fonctionne avec la commande suivante :
sudo modprobe drbd
Si tout se passe bien, elle ne devrait remonter aucune erreur. En revanche, si vous n’avez pas un kernel avec une version compatible, vous devriez avoir une erreur du type “file not found”. Dans ce cas-là, il faudra compiler DRBD à la main.
Préparation des machines
Les serveurs doivent évidemment pouvoir se joindre et se résoudre. Le mieux étant bien sûr un DNS correct, on pourra se rabattre dans le cadre d’un test sur a minima un fichier /etc/hosts contenant les informations nécessaires :
192.168.100.11 drbd1 drbd1.example.org
192.168.100.12 drbd2 drbd2.example.org
Ensuite, j’ai créé, sur chaque serveur, deux partitions de 8 Go chacun sur le disque de 16. La première sera de type Linux, la seconde sera de type LVM.
On oublie pas de créer les objets LVM pour pouvoir les utiliser plus tard.
pvcreate /dev/sdb2
vgcreate vg_drbd /dev/sdb2
lvcreate -n lv_drbd -l 2047 vg_drbd
Configuration
Le fichier de configuration global de DRBD est /etc/drbd.conf. Il définit les fichiers unitaires qui doivent être modifiés. Le fichier /etc/drbd.conf en lui-même ne doit donc pas être modifié directement ; sauf dans le cas où on souhaite changer les fichiers de configuration inclus de répertoire.
cat /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
Le fichier suivant doit contenir les paramètres et les commandes qui sont globaux à toutes les ressources DRBD.
cat /etc/drbd.d/global_common.conf
# DRBD is the result of over a decade of development by LINBIT.
# In case you need professional services for DRBD or have
# feature requests visit http://www.linbit.com
global {
[...]
Template de ressource
Pour rendre la configuration lisible, on sépare les fichiers de configuration de manière à faire un fichier texte par ressource, nommé avec la convention r[nombre].res. Ici on prendra l’exemple le plus simple d’une synchronisation synchrone (protocole C, par défaut) dans un modèle actif/passif. Pour vous aider à créer vos premières ressources, DRBD met à disposition, dans /etc/drbd.d/drbdctrl.res_template un template dans lequel vous n’aurez qu’à modifier les valeurs.
resource .drbdctrl {
net {
cram-hmac-alg sha1;
shared-secret "<your-shared-secret>";
}
volume 0 {
device /dev/drbd0 minor 0;
disk /dev/mapper/<vgname>-.drbdctrl;
meta-disk internal;
}
on <node_1> {
node-id 0;
address <ipaddress>:<port>;
}
on <node_n> {
node-id <n>;
address <ipaddress>:<port>;
}
connection-mesh {
hosts <node_1> <node_2> ... <node_n>;
net {
protocol C;
}
}
}
Ressource pour un disque “simple”
Ici, c’est l’exemple le plus simple. On va indiquer que notre ressource est distribuée sur 2 serveurs sur un bête partition Linux. Les metadata, elles, sont stockées en local (ce qui n’est pas forcément le mieux, mais pour commencer ça suffira).
vi /etc/drbd.d/r0.res
resource r0 {
on drbd1 {
device /dev/drbd1;
disk /dev/sdb1;
address 192.168.100.11:7789;
meta-disk internal;
}
on drbd2 {
device /dev/drbd1;
disk /dev/sdb1;
address 192.168.100.12:7789;
meta-disk internal;
}
}
Note : si le protocole de synchronisation n’est pas spécifié, on est en synchronisation synchrone par défaut.
Attention : chaque ressource déclarée réserve le port TCP pour la communication de la ressource. Il faut donc incrémenter le numéro du device drbd ET incrémenter le numéro de port à chaque nouvelle ressource (et aussi s’assurer que le port est libre…).
Pour mes tests, j’ai également utilisé la possibilité offerte par DRBD d’utiliser des volumes LVM plutôt que des partitions brutes. La configuration est la même à ceci près qu’on pointe sur le LV plutôt que sur une partition.
vi /etc/drbd.d/r1.res
resource r1 {
on drbd1 {
device /dev/drbd2;
disk /dev/vg_drbd/lv_drbd;
address 192.168.100.11:7790;
meta-disk internal;
}
on drbd2 {
device /dev/drbd2;
disk /dev/vg_drbd/lv_drbd;
address 192.168.100.12:7790;
meta-disk internal;
}
}
Initialisation
Maintenant que tout est configuré, on va pouvoir déclencher l’étape d’initialisation des metadata et des ressources nouvellement créées. Lancez les commandes suivantes sur les deux nœuds :
drbdadm create-md r0
drbdadm create-md r1
drbdadm up r0
drbdadm up r1
Une fois que les commandes sont lancées, on peut afficher les informations sur l’initialisation des disques (état normal) avec drbdmon.
Actuellement, les nœuds sont Inconsistants et en Secondaire/Secondaire, car nous n’avons pas encore désigné le nœud principal. Nous allons “forcer” le sens dans lequel le disque doit être synchronisé.
Sélectionner un des nœuds, qu’on va désigner comme “serveur primaire” et exécuter les commandes suivantes (uniquement sur lui) :
root@drbd1:~# drbdadm primary --force r0
root@drbd2:~# drbdadm primary --force r1
ATTENTION : dans le cas d’un disque déjà créé, il faut bien ne pas se tromper de sens, au risque d’écraser le disque qui contiendrait les données.
Une fois la synchronisation terminée, on peut utiliser le disque /dev/drbdX.
C’est fini ?
En fait, pas tout à fait. On ne va pas pouvoir utiliser nos disques exactement comme des disques classiques. Si vous formattez ce disque en ext4/xfs/whatever et que vous essayez de le monter sur vos deux serveurs drbd1 et drbd2, vous allez avoir une drôle de surprise.
En effet, ces filesystems ne savent pas gérer les accès concurrents provenant de deux machines simultanées. On va donc devoir :
- soit utiliser un filesystem capable de gérer les accès concurrents (page Wikipedia listant quelques clustered filesystems) comme OCFS2 ou GFS2. Si vous publiez les disques DRBD en iSCSI pour votre cluster VMware, vous n’aurez pas de problème non plus car le VMFS le gère très bien aussi.
- soit s’assurer à tout moment que le disque n’est monté que sur un seul serveur à la fois.
Évidemment la 2ème option est à proscrire si vous êtes dans un contexte de production. Cependant, cela reste possible si vous montez un cluster Pacemaker ou RHCS par exemple, qui va s’assurer que les bascules de stockage se font de manière propre.
Enjoy !
Bonus : quelques commandes utiles
Pour une ressource donnée, afficher le rôle du serveur local
root@drbd1:~# drbdadm role r0
Primary
root@drbd1:~# drbdadm role r1
Secondary
Afficher de manière concise l’état d’une ressource sur les nœuds
root@drbd1:~# drbdadm dstate r0
UpToDate/UpToDate
root@drbd1:~# drbdadm dstate r1
Inconsistent/UpToDate
Afficher plus de détails sur une ressource avec drbdadmin pour un résultat simple ou drbdsetup pour avoir plus de détails :
drbdsetup status r1 --verbose --statistics
r1 node-id:1 role:Secondary suspended:no
write-ordering:flush
volume:0 minor:2 disk:Inconsistent quorum:yes
size:8384220 read:0 written:1972628 al-writes:0 bm-writes:0 upper-pending:0 lower-pending:0 al-suspended:no blocked:no
drbd2 node-id:0 connection:Connected role:Primary congested:no ap-in-flight:0 rs-in-flight:0
volume:0 replication:SyncTarget peer-disk:UpToDate done:23.53 resync-suspended:no
received:1972628 sent:0 out-of-sync:6411740 pending:3 unacked:12 dbdt1:92.39 eta:68
En temps normal, toutes les ressources sont actives par défaut. Cependant, on peut les activer ou les désactiver à la main :
drbdadm up r0
drbdadm down r1
# utiliser le mot clé « all » pour désigner toutes les ressources
Si on modifie les fichiers de configuration global ou un fichier de ressource, il est nécessaire de mettre à jour la configuration sur les deux nœuds. Il est possible de reconfigurer les ressources même si elles sont opérationnelles grâce à la méthode suivante :
drdbadm adjust r0
Changer le statut du nœud courant (pour le passer en primary s’il est secondary par exemple)
drbdadm primary r1
drbdadm secondary r0