Et si on faisait un nuage de points avec Kibana ?
Si vous me suivez sur les réseaux sociaux que je fréquente (Twitter et LinkedIn) vous ne pouvez pas avoir loupé le fait que je participe à l’organisation du sondage annuel sur les salaires dans la tech Girondine de l’association Okiwi. (OUI, je vous ai bassiné avec ça, mais c’est pour la bonne cause :chatpotté:).
Aujourd’hui, j’en parle pas, promis ;-p (ou alors, juste un tout petit mini lien ?).
Cet article est juste un retour d’expérience suite à un problème que j’ai eu, dans le cadre de ce sondage.
Frédéric Camblor m’a fait remarquer que pour visualiser les différents types de salaires en fonction de certaines catégories, un nuage de points pouvait être une visualisation efficace.
Or, pas de bol, on ne peut pas nativement faire ce type de visualisation dans Kibana… Et vous allez voir que la solution est tout sauf triviale…
Déjà, comment le savoir ?
Pour en avoir le coeur net, j’ai épluché toutes les possibilités offertes par la page “Visualisation” de mon Kibana.
D’abord, il y a Lens, a priori c’est relativement récent car ça ne me disait rien, mais c’est une façon assez pratique, user friendly et intuitive de créer des visualisations.
On drag’n’drop la métrique qu’on veut représenter et Kibana nous propose une ou plusieurs visualisation avec un type d’aggregation (count, avg, median) déterminé automatiquement.
Pour l’avoir utilisé pour la première fois pour le sondage des salaires de cette année, c’est hyper bien pensé et j’ai gagné beaucoup de temps par rapport à l’ancien éditeur de visualisation.
Bravo Elastic pour ça.
Ensuite, il y a l’ancienne façon de faire des visualisations, et là encore, pas de nuage de points…
Enfin, il y a les TSVB mais c’est pour les timeseries (donc là ça va pas le faire), et… Vega…
C’est quoi, Vega ?
Nouveauté dans Kibana 6.2 : vous pouvez désormais construire des visualisations riches Vega et Vega-Lite avec vos données Elasticsearch.
Vega-Lite is a high-level grammar of interactive graphics. It provides a concise, declarative JSON syntax to create an expressive range of visualizations for data analysis and presentation. – https://vega.github.io/vega-lite/
Grosso modo, pour tout ce que Kibana ne propose pas nativement comme type de visualisation, on vous propose de vous orienter vers le langage Vega, qui permet de déclarer, en JSON, des graphiques assez complexes et spécifiques à votre besoin.
Cool ! Reste plus qu’à trovuer comment ça fonctionne ce biniou, et surtout, comment ça s’interface avec les données dans mon ElasticSearch…
La première chose que j’ai cherché, c’est donc des exemples de nuages de points en Vega. Sauf que… je n’avais aucune idée de comment dire “nuages de points” en anglais (la recherche en Français n’ayant rien donné). Et non, ce n’est pas “cloud dots”…
Une fois que je savais que c’était un “bubble chart”, c’était tout de suite beaucoup plus simple ;-) et j’ai trouvé un tuto qui commençait à ressembler à ce que je voulais faire (même si au final ce que j’ai fais ne ressemble pas du tout).
Bubble Chart in Kibana with Vega
Ca ressemble à quoi, Vega ?
Si vous cliquez sur “Custom Visualization”, vous allez tomber sur cette page dans votre Kibana :
A gauche, un aperçu de ce que vous êtes en train de faire, et à droite, le code JSON associé.
Il y a pas mal de gloubiboulga mais vous allez vite vous rendre compte que c’est surtout des commentaires pour vous aider à comprendre ce que vous êtes censé écrire pour que ça fonctionne.
Si vous enlevez tous les commentaires, vous devriez tomber sur ça :
{
$schema: https://vega.github.io/schema/vega-lite/v5.json
title: Event counts from all indexes
data: {
url: {
%context%: true
%timefield%: @timestamp
index: _all
body: {
aggs: {
time_buckets: {
date_histogram: {
field: @timestamp
interval: {%autointerval%: true}
extended_bounds: {
min: {%timefilter%: "min"}
max: {%timefilter%: "max"}
}
min_doc_count: 0
}
}
}
size: 0
}
}
format: {property: "aggregations.time_buckets.buckets"}
}
mark: line
encoding: {
x: {
field: key
type: temporal
axis: {title: false}
}
y: {
field: doc_count
type: quantitative
axis: {title: "Document count"}
}
}
}
La difficulté de faire du Vega dans Kibana a été pour moi que je découvrais 2 choses en même temps :
- requêter elastic depuis Kibana avec des notions d’aggregations, buckets, etc que je ne maitrisais pas du tout
- découvrir le langage Vega

Choisir l’index
La première chose qu’on remarque, c’est que les données récupérées d’ElasticSearch et donné à manger à Kibana proviennent de TOUS nos index car on a la ligne index: _all.
data: {
url: {
%context%: true
%timefield%: @timestamp
index: _all
Clairement, ça va pas le faire ;-) du coup on restreint à l’index qui nous intéresse (okiwi-2022 dans mon cas)
Requêter Elastic avec des aggrégations
Le deuxième gros morceau à comprendre, c’est la partie interrogation de notre ElasticSearch
body: {
aggs: {
time_buckets: {
date_histogram: {
field: @timestamp
interval: {%autointerval%: true}
extended_bounds: {
min: {%timefilter%: "min"}
max: {%timefilter%: "max"}
}
min_doc_count: 0
}
}
}
size: 0
}
Ici, l’exemple fait un graphique en fonction du temps (x-axis). Les données sont regroupées avec une aggrégation de type date_histogram, avec un intervalle automatique et en se basant sur le timestamp de nos entrée dans ElasticSearch.
Ce que j’ai mis un bon moment à comprendre (car la doc est pas ouf non plus et j’ai perdu beaucoup de temps dessus) c’est qu’on a pas forcément BESOIN de faire des aggrégations.
Les aggregations possibles, si vous, vous en avez besoin, sont disponibles ici
- https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket.html
- https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-pipeline.html
Typiquement, dans mon cas, je ne voulais pas afficher un point (genre la moyenne) pour un groupe de personne de mon sondage, mais bien un point par personne !
Requêter Elastic sans aggrégation
Pas besoin d’aggrégation donc…
Il m’a fallu un bon moment pour trouver car tous les exemples que j’ai trouvé sur Internet passaient TOUS par des aggrégations préalables, mais j’ai fini par trouver comment juste faire une requête à ElasticSearch depuis Kibana de la façon suivante (depuis les “Dev Tools” ou bien un cURL) :
GET okiwi-2022/_search
{
"size": 10,
"_source": ["Nombre d'années d'expérience", "Salaire *partie fixe BRUT* (€) annuel (ex_ 30000)_ ", "Type d'entreprise"]
}
Ici, je requête l’index okiwi-2022 et je lui demande 10 résultats contenant les propriétés “Nombre d’années d’expérience”, “Salaire partie fixe BRUT (€) annuel (ex_ 30000)_ “, “Type d’entreprise” de mes documents.
Une fois que je savais ça, j’ai juste testé dans Vega
body: {
"size": 1000,
"_source": ["Nombre d'années d'expérience", "Salaire *partie fixe BRUT* (€) annuel (ex_ 30000)_ ", "Type d'entreprise"]
}
Bon ok, ça marchait toujours pas 😭😭😭 mais j’avais progressé.
La blague, c’est que le JSON renvoyé par Elasticsearch est un poil différent en fonction du fait que vous utilisiez ou non une aggregation.
Dans le premier cas, les données sont encapsulées dans aggregations.time_buckets.buckets, d’où la ligne suivante, en dessous du bloc “data”
format: {property: "aggregations.time_buckets.buckets"}
Dans le cas où vous avez une requête sans aggrégation, il suffit “juste” de remplacer par
format: {property: "hits.hits"}
Le graphique en lui même
OK, maintenant, on a les données, on peut faire du Vega purement cosmétique.
La première chose que j’ai voulu changer, c’est que dans l’exemple donné quand on créé le graphique, on a des traits. Or, moi je veux des points.
Ca, c’est géré par la ligne :
mark: line
On remplace ça par :
mark: {"type": "point"}
Et puis pour que le graphique soit plus “user friendly”, on peut activer les tooltips pour voir les détails du point quand on passe la souris dessus
mark: {"type": "point", "tooltip": true}
Et puis comme les points sont trop petits (30 de base), on peut grossir un peu
mark: {"type": "point", "tooltip": true, size: 80}
Les axes
Normalement notre graphique est pété depuis nos premières modifs car l’exemple donné par Kibana se base sur des axes temporels et des données récupérées depuis une aggrégation et qu’on a viré tout ça.
Il est donc grand temps de rebosser sur les axes et surtout où on place nos points (en fonction de quels axes).
Cette partie est gérée par le bloc encoding
encoding: {
x: {
field: key
type: temporal
axis: {title: false}
}
y: {
field: doc_count
type: quantitative
axis: {title: "Document count"}
}
}
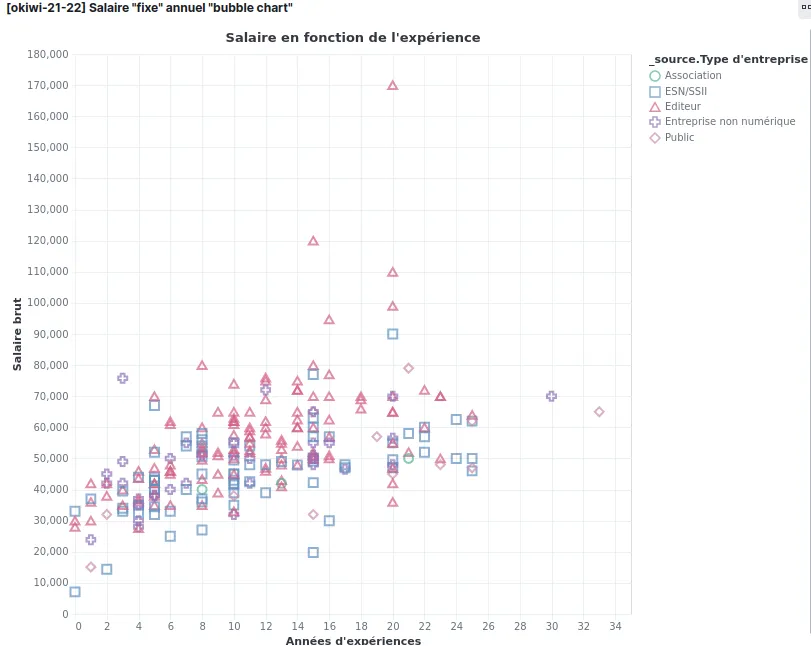
Dans mon exemple, je veux afficher le salaire des gens en fonction de leur expérience. Mon axe des X est donc le nombre d’années d’expérience et celui des y est donc le salaire.
x: {
field: "_source.Nombre d'années d'expérience"
type: "quantitative"
axis: {title: "Années d'expériences"}
}
y: {
field: "_source.Salaire *partie fixe BRUT* (€) annuel (ex_ 30000)_ "
type: quantitative
axis: {title: "Salaire brut"}
}
Pour faire joli, je leur ai donné un titre avec axis: {title: ""}, c’est quand même plus sympa que le nom dégueulasse que j’ai importé du google forms en CSV ;-). Dans les deux cas, mes axes sont “quantitatifs” et non plus “temporels”. La documentation Vega sur les axes est disponible ici
Une fois que tout ça est fait, ça devrait donner un truc qui ressemble grosso modo à ça (la requête à droite est pas la bonne mais le résultat est le même):
Rendre ça joli
On n’est plus très loin de ce que Frédéric m’a proposé en début d’aticle. Reste maintenant à discriminer visuellement les données en fonction du type de société dans laquelle le salarié est embauché.
Pour ça, on va changer la forme ET la couleur du point en fonction d’une 3ème donnée : son type d’entreprise.
Bon, je vais le dire tout de suite, j’ai passé pas mal de temps sur cette partie et je ne suis pas réussi à faire ce que je voulais malgré plusieurs essais…
La méthode pour faire ça est d’utiliser les valeurs shape et color dans encoding. Là où Vega est plutôt malin, c’est que si vous mettez la même valeur comme field dans shape et color, les deux sont “merge” dans la légende, comme le montre cet exemple de la doc de Vega
shape: {"field": "_source.Type d'entreprise", "type": "nominal"}
color: {"field": "_source.Type d'entreprise", "type": "nominal"}
Sauf que les couleurs choisies par Kibana (qui utilise sa propre scale) sont plus que bof…
En relisant la doc, on voit qu’on devrait pouvoir choisir notre propre scale
The range of an ordinal scale can be an array of desired output values, which are directly mapped to elements in the domain. Both domain and range array can be re-ordered to specify the order and mapping between the domain and the output range. For ordinal color scales, a custom scheme can be set as well.
Sauf que tous mes tests se sont révélés être des échecs :-( Au mieux, j’ai réussi à le faire, mais en pétant la légende.
color: {mark: {"type": "point", "tooltip": true, size: 60}
"type": "nominal",
"scale": {
domain: ["Association", "ESN/SSII", "Editeur", "Entreprise non numérique", "Public"]
range: ["rgb(230,230,31)", "rgb(255,0,0)", "rgb(0,191,0)", "rgb(31,31,255)", "rgb(191,31,191)"]
}
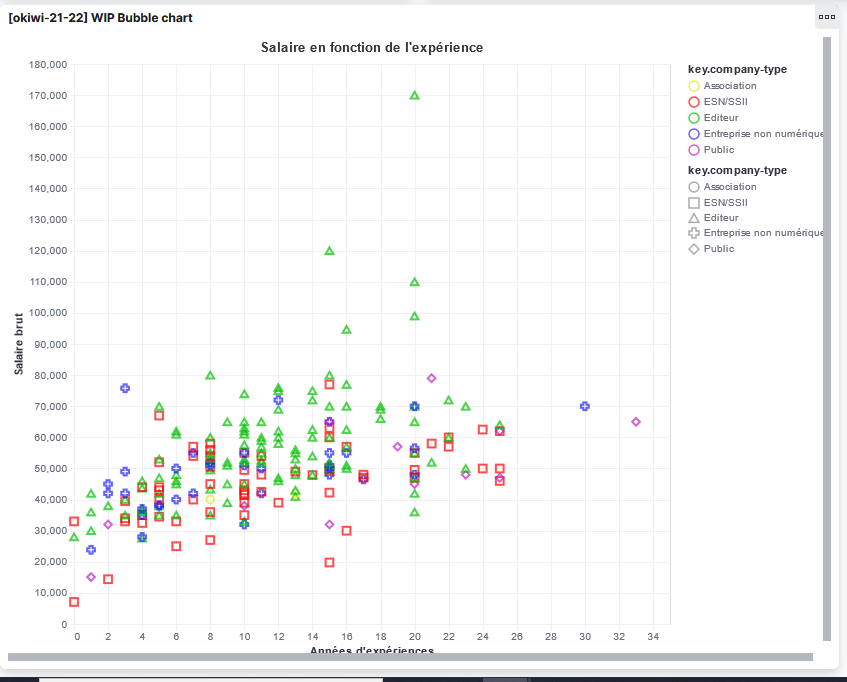
Conclusion
Ce “besoin” de faire un graphique non prévu “out of the box” dans Kibana m’aura permi de découvrir plusieurs choses. D’abord, les différentes façon de requêter ElasticSearch car je n’avais jamais eu besoin de le faire (au delà de sortir les documents entier avec un bête index/_search sans filtres).
Ensuite, j’ai réussi à faire un graphique approchant de ce que je voulais faire.
Et enfin, ça m’a surtout permis de voir que je pouvais totalement me passer de Kibana pour faire des visulisations jolies.
Car beaucoup de gens qui font du Vega utilisent tout simplement une URL pointant vers un CSV et c’est totalement suffisant pour afficher des graphiques sur Internet… On perd le côté interactif bien sûr, mais pour les cas où j’ai besoin de quelque chose de simple, ça me suffira largement.
Mise à jour mars 2026 : le serveur Kibana a été décommissionné. Les dashboards interactifs ne sont plus disponibles. Les captures d’écran et les exports de données sont consultables dans l’article dédié à la décommission.
Have fun :-)
Sources
- https://www.elastic.co/fr/blog/getting-started-with-vega-visualizations-in-kibana
- https://vega.github.io/vega-lite/examples/circle_bubble_health_income.html
- https://www.elastic.co/fr/blog/custom-vega-visualizations-in-kibana
- https://www.elastic.co/guide/en/kibana/6.7/vega-querying-elasticsearch.html
- https://discuss.elastic.co/t/bubble-chart-with-ratios/185128