Introduction
Note : cet article a été co-écrit avec mon ex-collègue Gaby Fulchic, alias Weeking.
Si vous avez vécu dans une grotte ces 10 dernières années et que vous n’avez jamais entendu parler de Kubernetes, eh bien… je vous invite à consulter mes autres articles sur le sujet xD.
Dans cet article, j’ai eu envie de creuser une fonctionnalité qui existe depuis un moment, mais dont j’ai rarement eu besoin : les HorizontalPodAutoscalers, en particulier via l’usage de custom metrics.
Prêt à scaler ? C’est parti !
C’est quoi diantre que l’autoscaling horizontal des pods (HPA) ???
L’HorizontalPodAutoscaler est une fonctionnalité de Kubernetes. Elle permet de spécifier, pour des métriques données sur un groupe de Pods, d’essayer d’atteindre des valeurs cibles. L’utilisation la plus basique de cette fonctionnalité est, vous l’aurez deviné, de “scaler” des Pods en fonction de métriques basiques, par exemple la consommation CPU.
Comme tout dans Kubernetes, il s’agit d’une API (actuellement autoscaling/v2). La manière la plus simple d’interagir avec elle est de créer un fichier manifest YAML où vous décrivez l’état souhaité de votre application en fonction de la charge.
Par défaut, seules des métriques simples, la consommation CPU et mémoire (celles collectées par metrics-server) sont disponibles afin de spécifier les règles de scaling.
Un exemple simple pourrait ressembler à ceci :
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
namespace: mynamespace
spec:
maxReplicas: 6
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
Note : Les spécifications HPA peuvent être incroyablement plus complexes et puissantes, car l’API s’est considérablement enrichie au fil des années. N’hésitez pas à aller lire la documentation officielle ;-).
Sur la base de l’exemple précédent, une fois le manifest appliqué, Kubernetes tentera de maintenir une utilisation moyenne du CPU autour de 50 % sur tous les pods “myapp” et ajoutera des replicas si la consommation moyenne de CPU dépasse ce seuil. Dès que la consommation CPU descend en dessous de la cible, Kubernetes réduit le nombre de replicas, jusqu’à atteindre le nombre minimal si nécessaire.
Bon, ça, c’est la théorie. Mais d’expérience, l’utilisation de HPA de cette manière présente des limites :
- Les applications modernes ont souvent des caractéristiques de performance complexes qui sont imparfaitement décrites par l’utilisation du CPU et de la RAM seules. Par exemple, une application peut être limitée par les entrées/sorties (I/O). D’autres facteurs comme la latence des requêtes, des métriques métier ou des indicateurs sur des dépendances externes (le nombre de messages dans une queue, par exemple) peuvent fournir une meilleure base pour les décisions de scaling.
- L’utilisation du CPU peut également être très élevée lors du « boot » d’un nouveau pod, ce qui peut entraîner plus de scaling que nécessaire (on, parle de boot storm sur les infrastructures plus classiques, je trouve le terme approprié).
L’HorizontalPodAutoscaler réagit aux métriques récupérées à un moment donné, ce qui signifie qu’il peut y avoir un décalage entre le pic de la métrique et la réponse de scaling. Cela peut entraîner une dégradation temporaire des performances. Trouver des métriques permettant d’anticiper le besoin de scaling plutôt que de réagir après une dégradation est donc l’objectif à garder en tête pour améliorer la fiabilité de nos apps.
Pour pallier ces limitations, Kubernetes permet l’utilisation de custom metrics offrant une plus grande flexibilité et un meilleur contrôle sur le comportement du scaling des applications. C’est là qu’interviennent des outils comme Prometheus et le Prometheus Adapter, qui vont nous permettre des stratégies d’autoscaling plus adaptées / efficaces.
Prometheus et les métriques via /-/metrics
Comme Kubernetes, Prometheus est un autre des grands projets sous l’égide de la CNCF. C’est un outil de collecte de métriques, qui dispose d’une base de données de séries temporelles (TSDB) optimisée pour stocker des métriques d’infrastructure et d’un langage de requête permettant des analyses profondes faciles, mais puissantes de ces métriques. Là aussi, j’ai déjà écrits plusieurs articles sur le sujet.
En général, on classe les outils de supervision dans deux grandes catégories. Ceux qui reçoivent les métriques des clients qui les « push » et ceux qui « pull » périodiquement les métriques des applications elles-mêmes. Prometheus utilise la stratégie de “pull” (la plupart du temps) et, par défaut, il va collecter nos métriques toutes les 30 secondes.
Cela signifie que vous n’avez pas besoin d’installer un « agent » sur vos applications MAIS que vous devez spécifier à Prometheus une liste de « cibles » qui exposent des points de terminaison HTTP (vos applications) servant des métriques dans un format spécifique, généralement sur le chemin /-/metrics :
$ kubectl -n mynamespace port-forward myapp-5584c5c8f8-gbsw8 3000
Forwarding from 127.0.0.1:3000 -> 3000
Forwarding from [::1]:3000 -> 3000
# dans un autre terminal
$ curl localhost:3000/-/metrics/ 2> /dev/null | head
# HELP http_request_duration_seconds duration histogram of http responses labeled with: status_code method path
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.0002"status_code="200"method="GET"path="/-/health"} 0
http_request_duration_seconds_bucket{le="0.0005"status_code="200"method="GET"path="/-/health"} 364
[...]
Nous pouvons ensuite interroger Prometheus pour obtenir ces métriques en spécifiant le nom de la métrique et en ajoutant des labels pour préciser quel sous-ensemble nous intéresse :
http_request_duration_seconds_bucket{kubernetes_namespace='mynamespace' kubernetes_pod_name="myapp-5584c5c8f8-gbsw8"}
Je vais partir du principe que vous avez un Prometheus disponible sur votre cluster pour la suite de l’article (sinon, allez jeter un œil au Prometheus Operator).
Grâce à Prometheus, nous avons maintenant une multitude de métriques parmi lesquelles choisir afin de prédire si nos applications doivent être mises à l’échelle de manière proactive. Cependant, le problème est que nous ne pouvons pas dire au HPA de surveiller directement ces métriques, car le HPA n’est pas directement compatible avec le langage de requête Prometheus PromQL.
Prometheus Adapter à la rescousse
Nous avons donc besoin d’un autre outil qui récupérera les métriques depuis Prometheus et les fournira à Kubernetes. Vous avez deviné de quel logiciel il s’agit maintenant : Prometheus Adapter.
On va l’installer à partir d’une chart Helm hébergée sur le dépôt prometheus-community :
$ helm show values prometheus-community/prometheus-adapter > values.yaml
$ helm install -n monitoring prometheus-adapter prometheus-community/prometheus-adapter -f values.yaml
$ kubectl -n monitoring get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
metrics-server 2/2 2 2 1d
prom-operator-kube-state-metrics 1/1 1 1 1d
prom-operator-operator 1/1 1 1 1d
prometheus-adapter 1/1 1 1 1d
prom-operator-query 3/3 3 3 1d
Dans cet exemple, vous pouvez voir que j’ai déjà déployé metrics-server et Prometheus en utilisant Prometheus Operator, et que Prometheus Adapter est en cours d’exécution.
Par défaut, Prometheus Adapter sera déployé avec certaines custom metrics que nous pouvons utiliser “out of the box” pour scaler nos applications plus précisément. Mais dans cet article, nous allons vous montrer comment créer ✨ vos propres ✨ métriques.
Configurer Prometheus Adapter pour exposer des custom metrics via l’API Server
Au départ, la configuration de Prometheus Adapter ne contient aucune règle. Cela signifie qu’aucune métrique personnalisée n’est exposée via l’API Server au début, et que HPA ne peut pas utiliser de custom metrics.
Prometheus Adapter fonctionne dans cet ordre :
- Découvrir des métriques en contactant Prometheus
- Les associer aux ressources Kubernetes (namespace, pod, etc.)
- Vérifier comment les exposer (si nécessaire, il peut renommer les métriques)
- Vérifier comment interroger Prometheus pour obtenir les valeurs réelles (ex. obtenir un “rate”).
D’abord, nous devons valider l’API des custom metrics sur notre cluster. La liste resources sera vide, mais cela prouve que l’API custom.metrics.k8s.io/v1beta1 est accessible.
└─[$] kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": []
}
Il faut ensuite plusieurs étapes pour que Prometheus Adapter collecte et fournisse des métriques au serveur API de Kubernetes. Toute la configuration de Prometheus Adapter peut être ajustée via le fichier values.yaml de la chart Helm.
La première chose à configurer ici est « où » Prometheus Adapter peut contacter Prometheus. Si Prometheus Adapter est exécuté sur le même cluster que la stack Prometheus, vous pouvez utiliser un enregistrement DNS interne (à Kubernetes) comme ci-dessous (voir la documentation Kubernetes DNS pour les services et pods). Sinon, vous pouvez spécifier une adresse IP (ou un nom DNS) et un numéro de port.
values.yaml > prometheus:
url: http://prom-operator-query.monitoring.svc
port: 9090
path: ""
Pour vérifier que Prometheus Adapter peut correctement contacter Prometheus, il vous suffit de vérifier les logs du pod (en utilisant kubectl logs pod/prometheus-adapter-abcdefgh-ijklm ou tout autre moyen à votre disposition pour lire les logs du pod).
Une fois cette partie opérationnelle, nous devons ajouter quelques règles à notre Prometheus Adapter.
Dans cet exemple, j’ai choisi d’utiliser une métrique appelée ELU (pour « Event Loop Utilization ») collectée à partir d’un serveur Node.js. Elle mesure combien de temps la boucle d’événements Node.js est occupée à traiter des événements par rapport à l’inactivité, et elle est plus représentative de la charge du serveur que le simple pourcentage de CPU.
Les règles nous permettent de spécifier quoi interroger dans Prometheus. Nous pouvons définir quels labels importer et, si nécessaire, les remplacer pour correspondre aux noms des ressources Kubernetes. Voici les valeurs les plus utiles à spécifier :
- seriesQuery: exécute la requête PromQL, éventuellement filtrée
- resources: associe les labels des séries temporelles aux ressources Kubernetes
- name: expose les séries temporelles avec des noms différents de ceux d’origine
- metricsQuery: méthode pour demander à Prometheus d’obtenir un taux («.GroupBy» signifie “group by Pod” par défaut)
values.yaml > rules:
default: false
custom:
- seriesQuery: 'elu_utilization{kubernetes_namespace!=""kubernetes_pod_name!=""}'
resources:
overrides:
kubernetes_namespace: {resource: "namespace"}
kubernetes_pod_name: {resource: "pod"}
name:
matches: ^elu_utilization$
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)
Vous devriez maintenant pouvoir obtenir quelques custom metrics avec des valeurs réelles en accédant au serveur API. Pour tester, nous allons utiliser kubectl et le paramètre --raw, qui nous donne plus de contrôle sur les requêtes envoyées au serveur API.
Voici quelques exemples de commandes que vous pouvez exécuter pour vérifier manuellement que les métriques sont correctement exposées via l’API Server :
# lister la découverte des custom metrics
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq
# lister les valeurs des custom metrics pour chaque pod
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/<namespace_name>/pods/*/elu_utilization" | jq
Attention : le scaling sera fortement dépendant de l’intervalle de scraping de vos métriques et de l’intervalle de découverte de votre Prometheus Adapter. La documentation officielle insiste sur le fait que vous pourriez rencontrer des problèmes si vous mettez une valeur trop basse.
“You’ll need to also make sure your metrics relist interval is at least your Prometheus scrape interval. If it’s less than that, you’ll see metrics periodically appear and disappear from the adapter.”
Comment cela va-t-il fonctionner ?
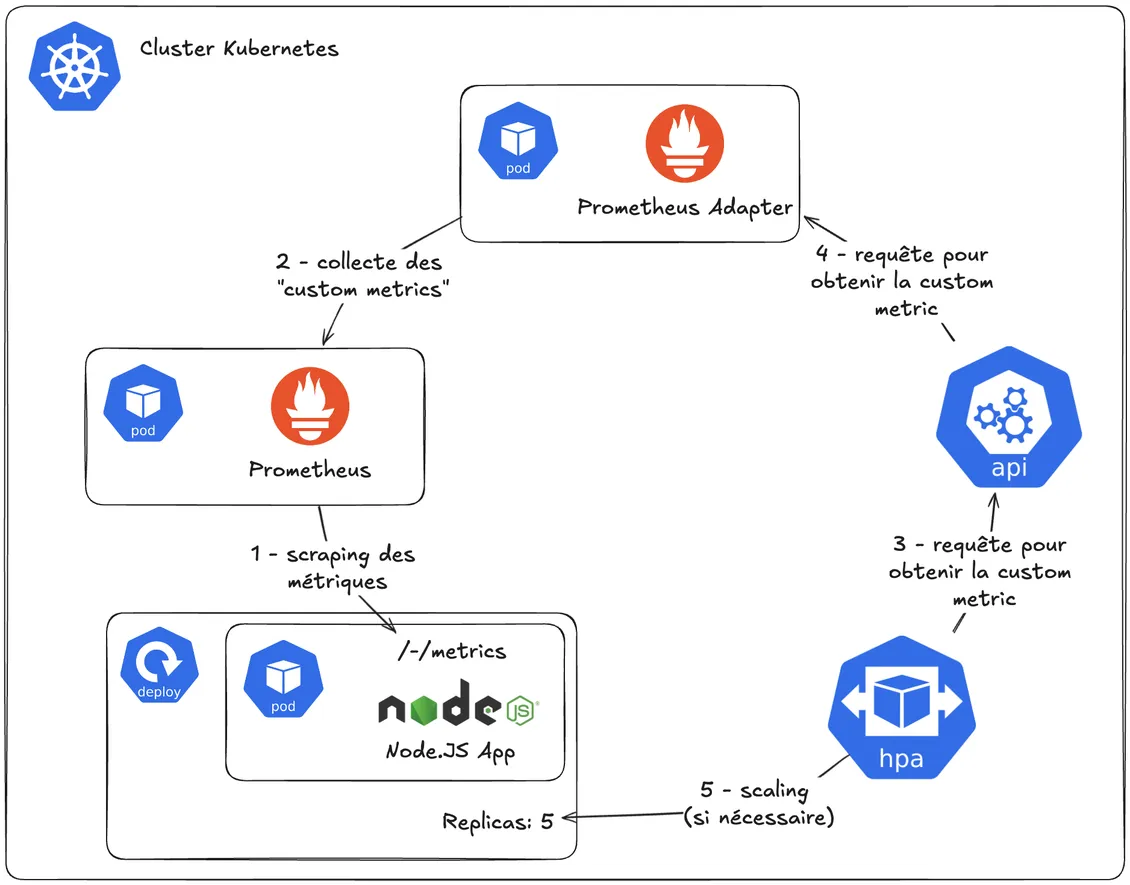
Jusqu’à présent, nous avons introduit plusieurs composants qui interagissent entre eux.
Mais comment tout cela va-t-il fonctionner sous le capot ? Eh bien, rien de mieux qu’un diagramme pour expliquer des choses comme celle-ci :
- Prometheus scrape les métriques exposées par notre application
- Prometheus Adapter interroge le serveur Prometheus pour collecter les métriques spécifiques que nous avons définies dans sa configuration
- L’HorizontalAutoscaler (le contrôleur qui gère les HPA) interrogera le serveur API pour vérifier périodiquement, si la métrique ELU est dans les limites acceptables…
- … qui à son tour demandera à Prometheus Adapter.
Créons maintenant notre premier HorizontalPodAutoscaler !
Utilisation d’une ressource HorizontalPodAutoscaler avec des custom metrics
Au début de ce post, nous avons introduit l’API HorizontalPodAutoscaler. La ressource elle-même n’est pas difficile à utiliser. En gros, HPA prend un déploiement cible à scaler, un nombre minimum de replicas, un nombre maximum de replicas et les métriques à utiliser. Pour la partie métrique, nous allons maintenant utiliser la métrique personnalisée de notre article configurée avec Prometheus Adapter :
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
spec:
maxReplicas: 6
metrics:
- pods:
metric:
name: elu_utilization
target:
averageValue: 500m
type: Utilization
type: Pods
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: <deployment.apps_name>
Lorsque vous configurez une ressource HPA, vous ne définissez que le nom de la métrique. Mais comment HPA peut-il déterminer la bonne métrique des bons pods puisque plusieurs applications peuvent exposer cette même métrique ? Pour comprendre cela, nous pouvons examiner les logs de Prometheus Adapter.
I0618 12:05:29.149095 1 httplog.go:132] "HTTP" verb="GET" URI="/apis/custom.metrics.k8s.io/v1beta1/n
Comme vous pouvez le voir, un labelSelector est ajouté à la requête. Et comme vous mentionnez le Deployment dans la référence scaleTargetRef de HPA, ce dernier utilise la valeur labelSelector du sélecteur de labels du Deployment. Cela vous permet de cibler les métriques d’un Deployment spécifique. Et ces labels existent parce que, lors du scraping des pods avec Prometheus, la découverte des pods Kubernetes et les annotations ajoutent des labels aux métriques.
Si vous souhaitez utiliser un labelSelector personnalisé dans la requête, ajoutez le champ metrics.pods.metric.selector à la ressource HPA.
Nous avons donc l’API des custom metrics, nous avons configuré Prometheus Adapter pour découvrir et exposer certaines métriques, et nous avons créé notre première ressource HPA. Il est maintenant temps de tester le déploiement sous charge et d’observer le comportement.
Pour cela, nous allons vous présenter un outil nommé Vegeta (it’s over 9000!)
Vegeta is a versatile HTTP load testing tool built out of a need to drill HTTP services with a constant request rate.
Nous allons utiliser Vegeta pour générer une charge sur notre application tout en surveillant les pods de l’application et l’état de l’HPA (avec 3 terminaux ouverts en parallèle) :
kubectl get hpa/<myhpa> -w -n <mynamespace>
kubectl get po -l app=<myapp> -w -n <mynamespace>
vegeta attack <app_endpoint_http>
Note : Dans le cas où votre application peut supporter une charge importante et que les paramètres par défaut ne déclenchent pas de scaling, vous pouvez modifier certains paramètres dans la commande Vegeta. Nous recommandons d’utiliser les options workers et rate :
- –workers : nombre initial de workers (par défaut 10)
- –rate : nombre de requêtes par unité de temps [0 = infini] (par défaut 50/1s)
Lorsque la charge augmente, la valeur de votre métrique personnalisée augmentera également, ce qui devrait à son tour déclencher une montée en charge du déploiement une fois que les seuils sont atteints.
Utilisation de Prometheus Adapter en production
Lorsque Prometheus Adapter devient un composant central de votre architecture, son tuning et sa surveillance deviennent essentiels.
Si ce composant est HS, votre HPA ne pourra plus réagir. Il y aura deux impacts potentiels : vous utiliserez trop de ressources pour le trafic actuel, ou au contraire, ne pas en avoir assez pour gérer le trafic. Dans tous les cas, vos workloads ne sont pas immédiatement affectés ; ils maintiennent le dernier nombre de replicas calculé par HPA avant la panne.
Pour éviter que cela ne devienne un SPOF, assurez-vous de mettre plus d’une replicas pour Prometheus Adapter. Et je conseille aussi de rajouter un petit PodDisruptionBudget pour éviter les soucis pendant les maintenances de votre cluster.
Conclusion
L’autoscaling horizontal des pods intégré à Kubernetes est un mécanisme standard pouvant potentiellement aider vos apps à gérer efficacement les charges variables. A titre personnel, je trouve le HPA classique, qui utilise les métriques CPU et mémoire, trop limité. Mais avec l’intégration des custom metrics avec Prometheus Adapter, on peut rendre ses décisions de scaling plus précises et pertinentes.
Si l’installation de Prometheus Adapter est simple, sa configuration est, je trouve, un peu contre-intuitive, voire complexe, sans pour autant gérer efficacement les scénarios les plus avancés.
C’est pourquoi je pense que, si vous n’avez pas comme impératif de rester sur le standard Kubernetes, vous devriez jeter un oeil (ou attendre mon prochain article ?) à KEDA (Kubernetes Event-Driven Autoscaling), un autre projet open-source qui étend les capacités de HPA en prenant en charge diverses sources d’événements et déclencheurs de scaling.
Bon scaling !
Sources supplémentaires
Documentation de Prometheus Adapter :
Documentation Kubernetes HPA :
Autre :