Introduction : quand l’IA rencontre le blogging technique
Ce n’est un secret pour personne, je ne suis pas hyper fan des blogueurs techs qui utilisent des LLMs pour rédiger des articles techniques à la pelle, sans saveur, parfois faux (parce que mal relus par l’humain derrière la machine). C’est la raison pour laquelle j’ai rédigé un AI manifesto et qu’on pourrait résumer avec la phrase suivante :
Je pars du principe que si je ne prends pas la peine d’écrire moi-même le contenu de ce blog, vous ne devriez pas prendre la peine de le lire.
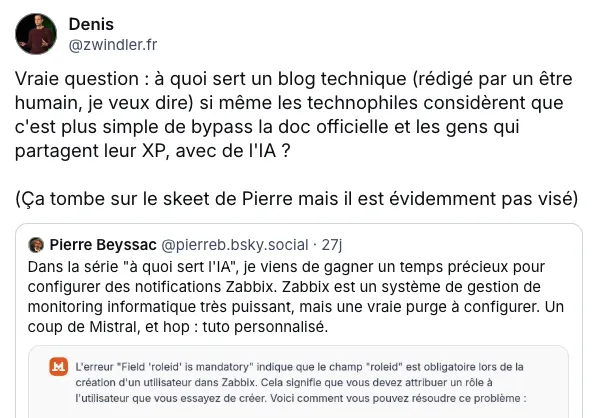
Cependant, j’ai exceptionnellement brisé cette règle aujourd’hui pour la rédaction d’un article “technique”, comme support d’une réflexion plus large que j’ai depuis quelques semaines maintenant. Question que j’ai d’ailleurs “posée tout haut” sur Bluesky et qui a eu des retours intéressants et même parfois inattendus.
Vraie question : à quoi sert un blog technique (rédigé par un être humain, je veux dire) si même les technophiles considèrent que c’est plus simple de bypass la doc officielle et les gens qui partagent leur XP, avec de l’IA ?
Plus globalement, la question était “est-ce que je ne me fais pas un peu de mal à rédiger des trucs techniques si les gens préfèrent le style fade des LLMs ?”
Vos réponses à cette question (qui n’en attendait pas forcément)
Je ne vais pas citer tout le monde, mais grosso modo, ce qui en ressort c’est :
- le blog tech, c’est avant tout pour son propre plaisir (d’écrire, d’apprendre)
- c’est une façon très efficace pour apprendre un nouveau sujet
- ça peut aider au moins une personne
- dans des cas très pointus ou niche, les LLMs ne rivalisent pas encore
- les LLMs ne peuvent pas “générer” un REX (enfin, pas un vrai :p)
- les LLMs ne vont pas faire des captures d’écrans pour les logiciels complexes qui ont des UIs
Les 4 premières réponses, je les attendais. C’est ce qui me motive à écrire ce blog depuis maintenant plus de 15 ans et c’est d’ailleurs assez proche de ce que je dis dans mon tout premier billet de blog de 2010.
Les trois dernières, je ne les avais pas forcément vues venir et c’est vraiment sur ça que je vais peut-être maintenant plus me reconcentrer : des REX et des sujets très pointus (qui étaient là aussi dans l’ADN du blog, surtout au début).
Mais il y a un point que personne n’a évoqué, c’est ce fameux style fade que je n’aime pas dans les LLMs. C’est générique, mécanique, lisse, (statistiquement) moyen.
Est-ce qu’avec un bon LLM aujourd’hui, on arrive à contourner cette limitation ?
Il se trouve que depuis peu, j’ai une licence Copilot pour le travail, avec accès à Claude Sonnet 4. J’ai donc décidé de tester le mode “Agent” sur mon blog (la machine a accès à tous les fichiers de mon workspace et peut écrire dans le workspace).
Note : c’est là où on voit que c’est pratique d’avoir tout en markdown dans un dépôt git !
J’ai donc décidé de prendre un sujet d’actualité (pour mon travail), que je connais plutôt bien, plutôt théorique mais surtout très bien documenté. Un exemple parfait d’article qu’on pourrait voir sur un blog généraliste généré par IA.
Version basique (en 2 prompts)
Prompt 1 : Demande initiale
Dans cette version basique, j’ai volontairement laissé beaucoup de liberté au LLM. Je lui ai juste donné le contexte du blog, lui ai demandé de “manger” quelques-uns de mes articles.
Il en a “consommé” 6 entre 2025 et 2023 sur différents thèmes, et un de 2015. Personnellement, j’ai pensé que ça serait beaucoup trop peu car les 6 articles étaient vraiment hétérocites (il y avait un billet d’humeur politique et une recette de cuisine dans le lot).
Contexte : Je suis auteur d'un blog technique, spécialisé dans l'observabilité et la virtualisation depuis 2010. Depuis 8 ans, je parle beaucoup de Kubernetes. De temps en temps j'écris des billets d'humeurs ou sur des sujets non tech. Le blog est rédigé en markdown avec hugo, dans le dossier content/post. La grande majorité des posts sont en Français.
Analyse le style d'écriture en lisant quelques posts.
Réponse 1 : Analyse du style
Ton et personnalité :
- Ton décontracté et accessible
- Humour et auto-dérision réguliers
- Émotions transparentes
Structure et organisation :
- Titres descriptifs et directs
- Introduction contextuelle
- Progression logique
Vocabulaire et expressions récurrentes :
- “Fun fact” pour les anecdotes
- “Stay tuned” pour les annonces
- Parenthèses humoristiques
- Émojis utilisés avec parcimonie
Évolution du style (2015 vs 2025) :
- 2015 : Plus formel, phrases longues
- 2025 : Beaucoup plus décontracté et personnel
Ce qui est noté ici est un résumé. En réalité, l’analyse était bien plus longue et j’ai été un peu bluffé par la précision de la réponse.
Il y a un peu de flagornerie par défaut dans les réponses des LLMs, il faut savoir lire entre les lignes, mais globalement c’était fidèle et intéressant d’avoir une analyse de la progression de mon style d’écriture.
La version 1 est disponible ici :
Prompt 2 : Création de l’article
Pour écrire l’article, j’ai essayé d’écrire un prompt relativement rapide. J’ai un peu triché par contre, je lui ai dit de se baser sur mon talk “SRE ! SRE partout !” dans lequel j’introduis les principes que j’avais envie de voir dans l’article écrit.
Est-ce que tu penses pouvoir écrire un article daté du jour sur les concepts SLO / SLI / error budget / critical user journey en copiant mon style ?
Indique qu'il ne faut pas confondre SLA et SLO
Tu peux aussi t'inspirer en partie d'un talk que j'ai écrit sur le sujet et qu'on peut trouver ici :
static/talks/2022-sre-sre-partout/index.md (À partir de la ligne 303)
Réponse 2 : Premier article généré
L’IA a produit un article complet qui reprenait effectivement mon style avec :
- Ton décontracté
- Structure progressive
- Exemples concrets
- Vulgarisation accessible
Le résultat est assez bluffant.
Avec un peu d’habitude, on peut deviner que ce n’est pas moi qui ai écrit l’article. Ma femme (qui lit la plupart de mes articles, a minima en diagonale) n’a pas su le dire à première vue.
Il y a quelques tournures que je n’aurais pas utilisées, mais surtout ça reste hyper généraliste (voire générique), lisse. En revanche, le ton est suffisamment décontracté pour que les détecteurs type ZeroGPT soient bernés :
12.62% : Votre Texte est probablement écrit par un humain, peut inclure des parties générées par une IA/GPT

Les parties surlignées en jaune sont les seules détectées comme “générées”.
Produire l’article dans cette version m’a pris à peu près 2 minutes chrono. Mais ça ne correspond toujours pas à mon standard de “blogging”.
Donc j’ai décidé de pousser l’expérience jusqu’au bout, quitte à passer plus de temps à prompter et lui donner des instructions que ça ne m’aurait pris à l’écrire moi-même.
Avec plus de prompts (version itérative)
Prompt X : Demande de modifications
Il y a tellement de modifications demandées ici, certaines tellement directives (exemples que je lui demande d’inclure), que j’ai quasiment envie de dire que c’est moi qui ai écrit une bonne moitié de l’article, pas le LLM… Mais c’était pour la science :p
L’article final est disponible ici :
Garde ce fichier tel quel, c'est une bonne première version
Écris un nouveau fichier avec le premier comme base, mais en prenant en compte les modifications suivantes (Tu as le droit de donner ton avis sur ces modifications tant que c'est constructif) :
De manière générale, je trouve qu'il y a beaucoup de listes (bullet points) ce qui ne correspond pas forcément à mon style (j'en mets mais pas aussi souvent)
En intro, j'aime bien fixer le contexte :
- Explique que c'est suite à des discussions avec des collègues développeurs pour qui les concepts n'étaient pas clairs que j'ai voulu redéfinir les termes, tels qu'ils ont été conçus par Google.
- Explique dès l'introduction que le SRE et tous les concepts associés dont les SLO, ont été inventés par Google.
Au niveau de "Et au-delà d'un certain seuil, les utilisateurs ne voient même plus la différence !", cite l'exemple d'un site web qui ne charge pas sur un smartphone. Au-delà d'un certain niveau de disponibilité, l'utilisateur ne saura pas dire si c'est son smartphone qui a un problème, son navigateur, le réseau 5G ou bien le site web qui rencontre un incident. Si recharger la page une fois de temps en temps suffit et que les utilisateurs ne sont pas plus impactés que ça, inutile d'investir dans plus de fiabilité
Explique également que pour les CUJ, la notion d'utilisateur du service n'est pas nécessairement "l'utilisateur final". L'utilisateur pour la fiabilité d'un service backend, ce n'est pas forcément l'utilisateur final, ça peut être le front qui initie le call. L'utilisateur de la CI, ce ne sont pas directement les utilisateurs finaux non plus, c'est les devs qui veulent livrer une nouvelle version de l'appli.
Explique qu'un microservice ne doit pas avoir trop de SLI, 3-4 les plus pertinentes et qui ont un sens métiers (cf les CUJ). Seuls les membres de l'équipe qui fournissent le service / le développent peuvent savoir (dans le sens : on ne peut pas en imposer des génériques pour toute une entreprise)
Dans les conseils pour définir des SLO cite aussi les méthodes USE et RED pour aider à concevoir des SLI fiables (définis-les très brièvement)
Enlève la phrase "tags pour moi même" en conclusion qui ne correspond pas à mon style "habituel"
Pour calculer les SLA / SLO tu peux citer le site https://uptime.is/
Pour le lien "mon talk sur le SRE en 2022", il faut mettre ce lien-là : /talks/2022-sre-sre-partout/index.html plutôt que /conferences/
Ajoute l'image /talks/2022-sre-sre-partout/binaries/simpsons.png dans la partie sur les error budgets qu'il faut consommer (c'est une blague qui montre une personne qui dit qu'elle casse régulièrement la prod pour finir sur le ton de l'humour)
Mets cette image en "image:" /talks/2022-sre-sre-partout/binaries/sre_sre_partout.jpg dans les métadonnées markdown des deux posts
Change le titre de la première version en y ajoutant "(en 2 prompts)", et le titre du second en y ajoutant "(en plusieurs prompts)"
Après avoir écrit tout ça, le résultat n’est pas mal, proche de ce que j’aurais pu écrire “moi-même” ou presque.
Si on compare le diff entre la version 1 et la version 2, on voit que quasiment TOUT a été réécrit.

Réflexions sur le processus
Ce qui marche VRAIMENT bien, c’est l’analyse de style : le LLM est capable d’identifier et de reproduire mes patterns stylistiques avec une précision surprenante par rapport au peu d’articles qu’il a analysé, au point de berner ma chérie sur une première lecture rapide.
Cependant, on reste sur quelque chose de super générique techniquement (qui a dit “chiant” ?). Sans guidage explicite, les exemples ne sont pas dingues, ça manque de contextualisation, etc. Il y a une grosse phase d’aller-retours avant que le résultat soit “correct” (aka “pas pénible à lire”) à mes yeux.
Je pense aussi qu’on aurait encore pu améliorer le résultat en demandant au LLM de lire plus d’articles de mon blog (ou en lui pointant ceux qui sont pertinents).
Enfin, Claude Sonnet 4 ne permet pas de générer des images donc si je voulais pousser l’expérience en ajoutant des schémas, il aurait fallu que je me contente d’outils textuels type mermaid, ou que je les ajoute à la main.
Conclusion ?
Que dire de tout ça ?
Déjà, Zero GPT ne sert à rien. Il a été totalement incapable de détecter que le texte avait été généré (à part quelques bribes).
Ensuite, je n’ai pas vraiment prévu de changer ma manière de blogger, même si j’y réfléchirai peut être à deux fois si j’ai un sujet très généraliste en tête. Je ferai peut être un peu plus de sujets “niches” et de REX.
Enfin, que “oui” on peut produire des articles plutôt pas mal (je trouve) avec un LLM, mais il faut (pour l’instant encore) :
- connaître le sujet
- passer pratiquement autant de temps (voire plus) à itérer sur le résultat pour avoir quelque chose de similaire à ce qu’un humain (moi) aurait pu écrire