
NOTE IMPORTANTE : cet article a été généré par un LLM. Ceci va à l’encontre de règles que je me suis fixé pour ce blog (cf l’AI Manifesto).
Je pars du principe que si je ne prends pas la peine d’écrire moi-même le contenu de ce blog, vous ne devriez pas prendre la peine de le lire.
Je l’ai fait dans le cadre d’une expérience qui est décrite dans l’article suivant :
Cependant, je ne vous interdit pas de lire cet article ci (les informations qu’il contient sur les SLOs sont correctes), je veux juste que vous le fassiez en connaissance de cause ;-P.
Introduction : quand les devs découvrent le SRE
Suite à plusieurs discussions récentes avec des collègues développeurs, je me suis rendu compte que les concepts SRE comme les SLO, SLI et Error Budget restaient flous pour beaucoup d’entre eux. Pourtant, ces notions sont de plus en plus utilisées dans nos équipes, souvent sans qu’on prenne le temps de bien les expliquer.
C’est donc l’occasion parfaite pour revenir aux fondamentaux et expliquer ces concepts tels qu’ils ont été conçus à l’origine par Google. Car oui, il faut le rappeler : le SRE (Site Reliability Engineering) et tous les concepts associés ont été inventés par Google, plus précisément par Ben Treynor Sloss en 2003, bien avant que DevOps ne devienne populaire !
L’idée de Google était simple : et si on demandait à des ingénieurs logiciel de concevoir une équipe d’exploitation ? De cette approche sont nés des concepts révolutionnaires pour mesurer et gérer la fiabilité des services.
Fun fact : j’avais déjà abordé ces sujets dans mon talk sur le SRE en 2022, mais je me dis qu’un article dédié ne fait pas de mal pour clarifier les choses :-).
SLA vs SLO : ne mélangeons pas tout !
Avant de rentrer dans le vif du sujet, petit aparté important : ne confondez pas SLA et SLO !
Le SLA (Service Level Agreement), c’est un contrat, souvent avec des pénalités financières si pas respecté. Genre “si le service est en panne plus de X heures dans le mois, on vous rembourse Y€”. Le SLO (Service Level Objective), c’est un objectif interne que vous vous fixez pour la fiabilité de votre service.
La différence est importante : les SLA sont souvent moins stricts que les SLO pour avoir une marge de manœuvre. Si votre SLA c’est 99,9% de disponibilité, votre SLO interne sera peut-être à 99,95%.
Bon, maintenant qu’on a éclairci ça, rentrons dans le détail !
Critical User Journey : commencer par ce qui compte vraiment
Est-ce que le client est content d’utiliser le service ?
C’est LA question fondamentale. Et pour y répondre, il faut d’abord identifier les Critical User Journey (CUJ), autrement dit les parcours utilisateurs critiques.
Mais attention, quand on parle d’utilisateur dans le contexte SRE, ce n’est pas forcément l’utilisateur final ! Pour un service backend, l’utilisateur peut être le frontend qui fait les appels API. Pour une plateforme de CI/CD, ce sont les développeurs qui veulent livrer une nouvelle version. Pour une base de données, ce sont les applications qui l’interrogent.
Concrètement, ça veut dire quoi ? Prenons l’exemple d’une plateforme e-commerce. Les CUJ pourraient être : un utilisateur peut rechercher et consulter un produit, il peut ajouter un produit au panier et passer commande, il peut se connecter à son compte.
On ne va pas définir des SLO pour toutes les fonctionnalités (la page “À propos” de votre site, on s’en fiche un peu), mais se concentrer sur celles qui, si elles tombent en panne, vont vraiment énerver vos utilisateurs.
Et c’est là que ça devient intéressant : définir les CUJ, c’est souvent un exercice qui doit impliquer le business, pas seulement les équipes techniques. C’est eux qui savent ce qui rapporte de l’argent !
SLI : mesurer ce qui compte
Une fois qu’on a identifié nos CUJ, il faut les mesurer. C’est là qu’interviennent les SLI (Service Level Indicators).
Un SLI, c’est simplement une métrique qui indique si votre service fonctionne bien du point de vue de l’utilisateur. Les plus classiques sont la disponibilité (pourcentage de requêtes qui réussissent), la latence (temps de réponse du service), le débit (nombre de requêtes traitées par seconde) et la qualité (pourcentage de réponses correctes, sans erreurs de données).
L’idée clé ici, c’est de mesurer depuis le point de vue de l’utilisateur, pas depuis vos serveurs. Peu importe que votre CPU soit à 10% si l’utilisateur voit des erreurs 500 !
Quelques conseils pour choisir vos SLI
Pour vous aider à concevoir des SLI fiables, vous pouvez vous inspirer des méthodes USE et RED. USE (Utilization, Saturation, Errors) se concentre sur les ressources systèmes, tandis que RED (Rate, Errors, Duration) se concentre sur les requêtes. Ces frameworks vous donnent un bon point de départ pour identifier les métriques qui comptent vraiment.
Mais attention, un microservice ne doit pas avoir trop de SLI ! Trois ou quatre SLI bien choisies et qui ont un sens métier valent mieux qu’une dizaine de métriques que personne ne regarde. D’ailleurs, seuls les membres de l’équipe qui fournissent le service peuvent vraiment savoir quelles sont les métriques pertinentes. On ne peut pas imposer des SLI génériques à toute une entreprise !
Exemple concret pour notre CUJ “recherche de produit” : SLI disponibilité pourrait être (requêtes HTTP 200 sur /search) / (total requêtes sur /search) * 100, et SLI latence 95% des requêtes sur /search répondent en moins de X ms.
SLO : se fixer des objectifs réalistes
Maintenant qu’on sait quoi mesurer, il faut se fixer des objectifs. C’est le rôle des SLO (Service Level Objectives).
Un SLO, c’est tout simplement une valeur cible pour vos SLI sur une période donnée. Par exemple : “99,9% des requêtes de recherche doivent réussir sur une période de 30 jours” ou “95% des pages de recherche doivent s’afficher en moins de 500ms sur une période de 7 jours”.
Quelques conseils pour bien définir vos SLO
Commencez par mesurer l’existant. Inutile de viser 99,99% si votre service actuel est à 98%. Regardez vos métriques historiques et fixez-vous des objectifs atteignables mais ambitieux.
Pensez S.M.A.R.T. : vos SLO doivent être Spécifiques, Mesurables, Atteignables, Réalistes et Temporellement définis. Comme tout bon objectif !
Et n’oubliez pas que 100% c’est mal ! Comme le dit si bien Ben Treynor Sloss (le papa du SRE chez Google) :
100% is the wrong reliability target for basically everything
Plus on veut de “9”, plus ça coûte cher exponentiellement. Et au-delà d’un certain seuil, les utilisateurs ne voient même plus la différence ! Prenez l’exemple d’un site web qui ne charge pas sur un smartphone : au-delà d’un certain niveau de disponibilité, l’utilisateur ne saura pas dire si c’est son smartphone qui a un problème, son navigateur, le réseau 5G ou bien le site web qui rencontre un incident. Si recharger la page une fois de temps en temps suffit et que les utilisateurs ne sont pas plus impactés que ça, inutile d’investir dans plus de fiabilité.
Pour vous aider à calculer ces pourcentages et temps d’indisponibilité, vous pouvez utiliser uptime.is qui fait les conversions pour vous.
Error Budget : retourner le problème
Et là, c’est le moment où ça devient vraiment malin. Au lieu de raisonner en “disponibilité”, les équipes SRE raisonnent en Error Budget (budget d’erreur).
C’est un simple changement de perspective : service accessible 99,9% = service inaccessible 0,1% du temps. Sur 30 jours, ça fait environ 43 minutes d’indisponibilité “autorisée”.
Cette approche change complètement la donne ! Au lieu de voir les pannes comme des échecs, on les voit comme un budget à dépenser intelligemment.
Comment utiliser son Error Budget ?
Contre-intuitivement… IL FAUT L’UTILISER !

Si votre SLO est respecté (utilisateurs contents), vous pouvez “dépenser” votre error budget pour faire des déploiements plus risqués, tester des nouvelles fonctionnalités en prod, faire du chaos engineering, ou réaliser des maintenances disruptives.
À l’inverse, si vous “cramez” votre error budget (SLO pas atteint), alors là, stop : on arrête tout ce qui n’améliore pas la fiabilité du service !
C’est un formidable outil de priorisation entre les équipes produit (qui veulent des nouvelles features) et les équipes ops (qui veulent de la stabilité). Le fameux mur de la confusion :
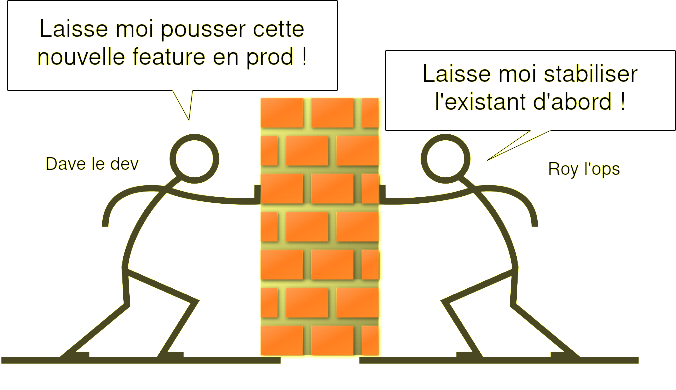
Exemple concret : une API de recommendation
Bon, assez de théorie, prenons un exemple concret. Imaginons qu’on ait une API de recommandation de produits.
D’abord, on définit le CUJ : “Un utilisateur doit pouvoir récupérer des recommandations personnalisées en moins de 1 seconde”. Ensuite, on choisit les SLI : disponibilité (réponses HTTP 200) / (total requêtes) * 100 et latence P95 du temps de réponse.
Pour les SLO, on pourrait avoir : “99,5% des requêtes sur l’API de recommandation doivent réussir sur 30 jours” et “95% des requêtes doivent répondre en moins de 800ms sur 7 jours”.
Enfin, on calcule l’Error Budget : 99,5% de disponibilité = 0,5% d’indisponibilité autorisée, soit environ 3,6 heures d’indisponibilité “budgetées” sur 30 jours.
Simple, non ?
Les pièges à éviter
Le premier piège, c’est de vouloir mettre des SLO partout. N’essayez pas ! Commencez par 2-3 SLO sur vos CUJ les plus critiques. Vous pourrez étendre ensuite.
Le deuxième piège, c’est de fixer des SLO trop stricts. Si vous mettez la barre trop haut, vous allez passer votre temps en “SLO violation” et personne ne prendra plus ça au sérieux.
Enfin, le troisième piège, c’est d’oublier l’aspect organisationnel. Les Error Budgets ne marchent que si toute l’organisation (business inclus) adhère au principe. Sinon, vous aurez beau être en SLO violation, on vous demandera quand même de déployer la nouvelle feature…
Comment commencer ?
Si vous n’avez jamais fait de SLO, voici un plan d’action simple.
Identifiez d’abord 1-2 CUJ critiques (avec le business !). Regardez ensuite vos métriques actuelles sur ces parcours. Définissez alors des SLO réalistes mais un peu ambitieux. Mettez en place l’alerting quand vous êtes en train de consommer votre error budget. Et enfin, itérez ! Les SLO ne sont pas gravés dans le marbre.
Conclusion
J’espère que cet article vous aura donné envie de creuser ces concepts ! Les SLO/SLI/Error Budget ne sont pas juste des buzzwords, c’est vraiment un changement de paradigme dans la façon d’appréhender la fiabilité.
Et le plus beau, c’est que ça marche autant pour une startup avec 3 développeurs que pour une GAFAM avec 10000 ingénieurs. L’important, c’est de commencer simple et d’itérer.
Pour aller plus loin, je vous recommande chaudement le SRE Book de Google (gratuit !) et leur guide pratique pour définir des SLO.
Et si vous voulez approfondir le sujet SRE en général, n’hésitez pas à jeter un œil aux slides de mon talk de 2022 ;-).
Bon monitoring !