Qu’est-ce que zeropod ?
Il y a un peu moins d’un an, j’avais publié un premier article sur un projet open source qui s’apelle zeropod.
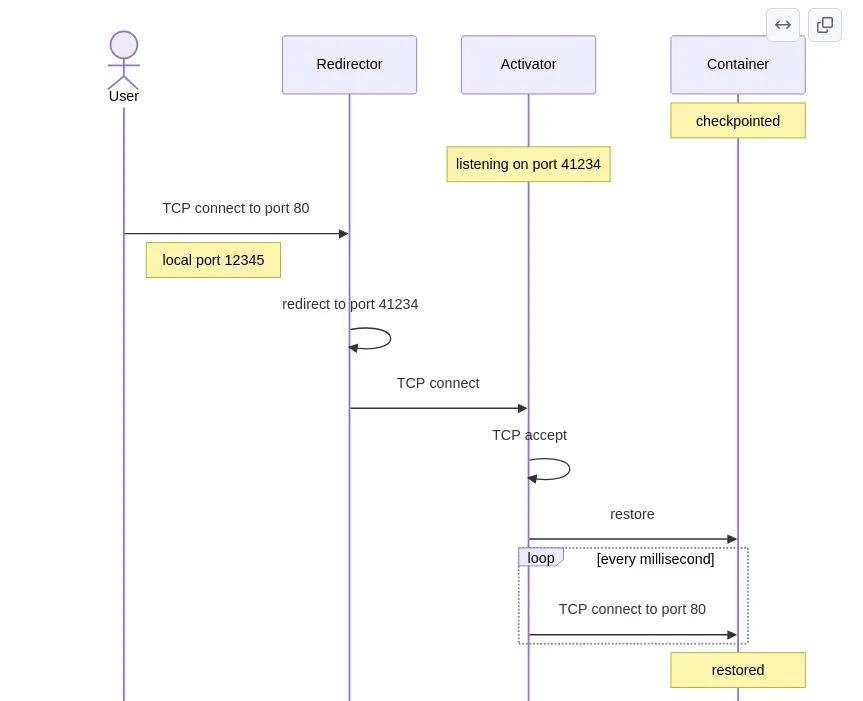
Zeropod is a Kubernetes runtime (more specifically a containerd shim) that automatically checkpoints containers to disk after a certain amount of time of the last TCP connection.
While in scaled down state, it will listen on the same port the application inside the container was listening on and will restore the container on the first incoming connection.
À l’époque, la version stable était la v0.6.x, et j’avais testé sur un cluster k3s. Les résultats étaient mitigés : ça marchait dans les grandes lignes, mais avec des limitations rédhibitoires pour une utilisation un peu sérieuse (probes impossibles, comportement flaky sous charge, temps de checkpointing un peu élevés à mon gout).
Entre temps, le projet a pas mal évolué (maintenant v0.12.0), avec des promesses de corrections et d’améliorations. J’ai donc remis le couvert pour voir où on en est vraiment.
Autre changement : j’ai abandonné k3s pour cette série de tests, pour des raisons que je détaillerai au fil de l’article.
Prérequis
Cette fois-ci, j’ai utilisé un serveur fraîchement provisionné chez mon hébergeur préféré :
- Un serveur Ubuntu 24.04.3 LTS (Noble), kernel 6.17.0-35 HWE, 7.7 Gi RAM, 100G disk
- Un cluster Kubernetes monté avec kubeadm, flannel comme CNI
- containerd vanilla
- local-path-provisioner (Rancher) pour avoir un stockage local
- Pas de cert-manager ni d’Ingress, on va au plus simple cette fois
Installation
J’ai déjà installé kubeadm plein de fois et certainement que vous aussi donc je ne vous fait pas l’affront de refaire un énième tuto.
# Installer kubeadm, kubelet, kubectl + containerd
sudo kubeadm init --pod-network-cidr=10.42.0.0/16
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
Une fois le cluster fonctionnel, l’installation de zeropod est triviale :
# Appliquer le kustomize générique
kubectl apply -k https://github.com/ctrox/zeropod/config/generic
# Ajouter un label à notre unique node
kubectl label node <votre-node> zeropod.ctrox.dev/node=true
# Vérifier que le pod tourne
kubectl -n zeropod-system wait --for=condition=Ready pod -l app.kubernetes.io/name=zeropod-node
C’est tout. Pas de flag spécial, pas de configuration supplémentaire. Sur kubeadm, kubelet est un binaire natif (/usr/bin/kubelet) détecté automatiquement par zeropod.
Note sur k3s : sur k3s, la documentation de zeropod est un peu différente puisque la config à utiliser est config/k3s. Le kustomize ajoute un flag -probe-binary-name=k3s sur l’initContainer pour que le shim sache que le kubelet est embarqué dans le binaire k3s. Lors de mes tests, j’ai constaté que même avec ce flag, le comportement n’était pas celui attendu (le socket tracker ne filtrait pas correctement les probes). Avec la config par défaut, le flag est sur l’initContainer mais pas sur le manager. J’avais suspecté qu’il y avait un autre composant à patcher, mais je n’ai pas creusé plus que ça.
Le DaemonSet déploie les images suivantes :
ghcr.io/ctrox/zeropod-manager:v0.12.0ghcr.io/ctrox/zeropod-installer:v0.12.0ghcr.io/ctrox/zeropod-criu:v4.2(CRIU a été mis à jour depuis v0.6.x)
Vérifions que la runtimeClass zeropod est bien disponible :
kubectl get runtimeclass
NAME HANDLER AGE
zeropod zeropod 30m
Premier test : nginx
Comme la dernière fois, commençons par un test simple avec nginx. On déploie un pod tout bête :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
annotations:
zeropod.ctrox.dev/scaledown-duration: 10s
labels:
app: nginx
spec:
runtimeClassName: zeropod
containers:
- image: nginx
name: nginx
ports:
- containerPort: 80
Le passage important, c’est l’annotation zeropod.ctrox.dev/scaledown-duration: 10s et runtimeClassName: zeropod.
Peu après le déploiement, zeropod détecte l’absence de trafic. Le container est checkpointé. Si on regarde les logs du manager :
{"time":"2026-05-29T14:26:37.269453861Z","level":"INFO","msg":"status event","container":"nginx","pod":"nginx-bench-7c65c8874-6pts7","phase":"RUNNING","duration":"0s"}
Puis 10 secondes plus tard :
{"time":"2026-05-29T14:26:47.465510937Z","level":"INFO","msg":"status event","container":"nginx","pod":"nginx-bench-7c65c8874-6pts7","phase":"SCALED_DOWN","duration":"191.259383ms"}
Le champ duration dans le log SCALED_DOWN correspond au temps de checkpoint : 191ms. C’est déjà nettement mieux que les ~400ms de v0.6.x sur k3s (probablement grâce à une mise à jour, peut être CRIU 4.2 ?).
Restauration
Quand on envoie une requête HTTP, le container se réveille :
time curl http://<POD_IP>/ -s -o /dev/null -w "%{http_code} (%{time_total}s)"
HTTP 200 (0.101s)
real 0m0.101s
user 0m0.003s
sys 0m0.003s
101ms pour restaurer nginx et servir une page. C’est comparable aux ~92ms de l’article original.
Petite nouveauté : sous v0.6.x, kubectl top pods retournait une erreur pour les pods checkpointés :
# v0.6.x
kubectl top pods
error: Metrics not available for pod default/php-xxx
Ce bug a été corrigé dans la v0.9.0. Désormais, les pods en SCALED_DOWN retournent 0m 0Mi :
kubectl top pods
NAME CPU(cores) MEMORY(bytes)
nginx 0m 0Mi
C’est plus élégant.
Test des liveness probes
C’était LA limitation majeure de la v0.6.x : zeropod était incompatible avec les probes Kubernetes. Si vous mettiez une liveness probe httpGet sur votre container, la sonde déclenchait le timer de scale-down, et votre container ne passait jamais en SCALED_DOWN. Résultat : probes inutilisables, donc zeropod inutilisable en production.
Ce qui a changé
Deux correctifs ont été apportés entre la v0.6.x et la v0.12.0 :
L’activator (le composant eBPF qui écoute le trafic pendant le SCALED_DOWN) : il intercepte les probes et répond 200 directement, sans réveiller le container. Ça, c’est le comportement “après scale-down”.
Le socket tracker (le composant qui ignore les connexions pendant l’état RUNNING) : depuis la PR #72 (merged août 2025), zeropod est capable de détecter les connexions provenant du kubelet et de ne pas les compter comme du “vrai” trafic. Ça, c’est le comportement “avant scale-down”.
Test grandeur nature
J’ai déployé nginx avec une liveness probe agressive (periodSeconds: 5) et un scaledown-duration: 10s :
spec:
runtimeClassName: zeropod
containers:
- image: nginx
name: nginx
livenessProbe:
httpGet:
path: /
port: 80
periodSeconds: 5
Sur k3s, ce test m’avait donné du fil à retordre : le socket tracker n’arrivait pas à filtrer les connexions des probes, qui resettaient le timer de scale-down en permanence. L’activator par contre (qui filtre les probes une fois le scale down passé) fonctionnait.
Sur kubeadm, le résultat est immédiat :
kubectl get pod -l app=nginx-probe -o json | jq -r '.items[0].metadata.labels["status.zeropod.ctrox.dev/nginx"]'
SCALED_DOWN
Le socket tracker filtre correctement les connexions du kubelet natif. La règle periodSeconds > scaledown-duration que j’avais dû utiliser sur k3s n’est plus nécessaire.
Un mot sur les évolutions entre v0.6.x et v0.12.0
Le tableau des améliorations entre les deux versions :
| Point | v0.6.x | v0.12.0 |
|---|---|---|
kubectl top pods en scaled-down | ❌ Erreur | ✅ 0m 0Mi (fix v0.9.0) |
| Checkpoint (nginx) | ~400ms | ~185ms (-54%) |
| Restauration (nginx) | ~92ms | ~99ms (stable) |
| CRIU | v3.x | v4.2 |
| Gestion d’échec checkpoint | basique | métriques + events (v0.11.0) |
| Proxy timeouts configurables | ❌ | ✅ (v0.11.0) |
| Migration inter-node | basique | améliorée + timeouts (v0.10.0) |
| Probes | ❌ Incompatible | ✅ Activator + socket tracker |
Note technique intéressante sur les flags CRIU : zeropod a retiré l’option --tcp-established en septembre 2025. Auparavant, les connexions TCP actives étaient sauvegardées et restaurées avec le container. Désormais, zeropod utilise --tcp-skip-in-flight (quand runc >= 1.3 le supporte). Conséquence pratique : si votre container a des connexions TCP sortantes au moment du checkpoint, elles seront perdues. Il faudra les rétablir après restore.
Déploiement de WordPress (le cas d’usage réaliste :trollface:)
Bon, nginx c’est bien, mais c’est pas très représentatif. Déployons une vraie app avec du PHP, Apache et une base de données.
Reprenons le manifest WordPress de l’article original, sans zeropod sur MySQL :
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
spec:
replicas: 1
selector:
matchLabels:
app: wordpress
template:
metadata:
annotations:
zeropod.ctrox.dev/scaledown-duration: 10s
zeropod.ctrox.dev/container-names: wordpress
zeropod.ctrox.dev/ports-map: wordpress=80
labels:
app: wordpress
spec:
runtimeClassName: zeropod
initContainers:
- name: wait-for-mysql
image: mysql:8
command:
- sh
- -c
- |
until mysql -h mysql -u root -p${MYSQL_ROOT_PASSWORD} -e "SELECT 1"; do
echo "Waiting for MySQL..."
sleep 3
done
mysql -h mysql -u root -p${MYSQL_ROOT_PASSWORD} -e "CREATE DATABASE IF NOT EXISTS wordpress;"
env:
- name: MYSQL_ROOT_PASSWORD
value: verySecurePassword
containers:
- image: wordpress:latest
name: wordpress
ports:
- containerPort: 80
env:
- name: WORDPRESS_DB_HOST
value: mysql
- name: WORDPRESS_DB_USER
value: root
- name: WORDPRESS_DB_PASSWORD
value: verySecurePassword
- name: WORDPRESS_DB_NAME
value: wordpress
MySQL (sans zeropod) :
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- port: 3306
selector:
app: mysql
clusterIP: None
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
serviceName: mysql
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- image: mysql:8
name: mysql
ports:
- containerPort: 3306
env:
- name: MYSQL_ROOT_PASSWORD
value: verySecurePassword
volumeMounts:
- mountPath: /var/lib/mysql
name: data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
Le checkpoint de WordPress (Apache + PHP) :
{"time":"2026-05-29T14:33:35.915988635Z","phase":"SCALED_DOWN","duration":"313.286787ms"}
Les checkpoints mettent autour de 300ms. La restauration est autour de 200 ms :
{"time":"2026-05-29T14:34:31.56806589Z","phase":"RUNNING","duration":"206.33005ms"}
La première requête curl confirme :
time curl http://<POD_IP>/ -s -o /dev/null -w "%{http_code} (%{time_total}s)"
HTTP 302 (0.212s)
212ms, c’est environ 2 fois plus rapide que les 454ms de l’article original.
Et maintenant, le test qui tue : cascade WordPress + MySQL
Dans l’article original, j’avais tenté le test ultime : mettre les deux pods (WordPress ET MySQL) avec runtimeClassName: zeropod, puis envoyer une requête HTTP sur WordPress pendant que les deux sont checkpointés.
Le scénario est le suivant :
- Au bout de quelques secondes, WordPress est SCALED_DOWN, MySQL est SCALED_DOWN aussi
- Un client envoie une requête HTTP à WordPress
- L’activator de WordPress intercepte la requête et restore le container WordPress
- WordPress (Apache+PHP) démarre, exécute le code PHP qui nécessite une connexion MySQL
- WordPress se connecte à MySQL sur le port 3306
- L’activator de MySQL intercepte la connexion et restore MySQL
- MySQL répond, WordPress génère la page, Apache renvoie la réponse HTTP
Du vrai scale to zero qui scale toute l’app, pas juste le front/back.
Note importante : je sais que vous ne voudrez probablement jamais scaler votre base de données à zéro en production, mais ce test montre que cette approche (eBPF + CRIU) fonctionne au-delà du simple scale-to-zero de serveurs web, ce que d’autres outils sur le marché font déjà très bien.
Sur k3s : pas de chance, sur kubeadm : victoire
Sur k3s, je n’ai pas encore réussi à faire fonctionner ce scénario : WordPress se restaurait mais ne répondait pas sur le port 80. J’ai passé pas mal de temps à essayer de comprendre, sans succès.
Même test, même version de zeropod, mais sur kubeadm :
curl http://<POD_IP>/ -s -o /dev/null -w "%{http_code} (%{time_total}s)"
HTTP 302 (0.224s)
224ms. Les deux pods sont passés de SCALED_DOWN à RUNNING, la page WordPress s’affiche. J’ai répété le test 5 fois de suite :
| Cycle | Temps (curl) | HTTP |
|---|---|---|
| 1 | 229ms | 302 |
| 2 | 192ms | 302 |
| 3 | 227ms | 302 |
| 4 | 230ms | 302 |
| 5 | 211ms | 302 |
Les logs zeropod confirment le réveil des deux containers :
WordPress: SCALED_DOWN → RUNNING
MySQL: SCALED_DOWN → RUNNING
Ce qui a vraiment changé depuis v0.6.x
Les probes (enfin !)
C’était mon grief principal dans le premier article. Aujourd’hui, c’est résolu :
- Avant : impossible de mettre des probes Kubernetes → zeropod inutilisable dans un usecase un minimum sérieux
- Après : l’activator intercepte les probes en SCALED_DOWN (répond 200 sans restore), et le socket tracker filtre les connexions kubelet en RUNNING
La stabilité
Le comportement flaky (perte de pods sous charge simultanée) a disparu. Là où j’avais des échecs sous l’article original, les tests de charge séquentiels et simultanés passent tous.
Les performances
Le checkpoint a gagné ~50% en vitesse (185ms vs 400ms). La restauration aussi (200ms vs 454ms). Merci CRIU v4.2 et les optimisations de zeropod.
kubectl top pods
Ce petit détail faisait tache — kubectl top pods plantait sur les pods checkpointés. Corrigé en v0.9.0.
Mais quelques limitations résiduelles
Je serais malhonnête si je disais que tout est parfait. Voilà ce qui reste problématique :
- depuis septembre 2025, zeropod n’utilise plus
--tcp-establishedpour CRIU. Ça veut dire que si votre container a des connexions TCP sortantes au moment du checkpoint, elles seront perdues. Dans la pratique, pour un serveur web, ça veut dire qu’il faut reconnecter la base de données après restore. Avec zeropod, la connexion MySQL est refaite automatiquement (la requête PHP en cours échoue, la suivante réussit). C’est un détail qui peut avoir son importance selon les cas. - Je n’ai testé que WordPress (Apache + mod_php) et MySQL. Les applications avec des websockets, du streaming, ou des connexions longues pourraient se comporter différemment.
- J’ai eu des difficultés à le faire correctement fonctionner sur k3s.
- J’ai observé un glitch (segfault Apache) sur le premier restore d’un pod WordPress fraîchement créé. Ce n’est pas reproductible après un cycle checkpoint/restore normal, mais si vous redéployez souvent vos pods, vous pourriez le rencontrer.
Verdict
Un an après, zeropod me parait un peu plus tenir ses promesses :
- Même si ce n’était pas rédhibitoire, le performances de checkpoint/restore se sont nettement améliorées (~50% plus rapide), ce qui est toujours bon à prendre
- Le support des probes Kubernetes a été ajouté, le blocage principal selon moi est levé
- La stabilité générale est meilleure
- Le test cascade (WordPress + MySQL) fonctionne
Je reste toujours aussi hypé par l’idée qu’on puisse freezer un container et le restaurer 10 secondes plus tard comme si de rien n’était. La magie de CRIU et d’eBPF combinés commence à se matérialiser, après des années d’attente.
Est-ce que je mettrais ça en production ? Disons que c’est moins risqué qu’il y a un an. Pour rigoler sur mon cluster perso, pourquoi pas. Pour une base de données en prod avec des connexions longues, je pense que je passe toujours mon tour ;-).
Mais franchement, pour le coup, le projet a bien évolué et mérite qu’on s’y attarde.